Rapidly Build a Highly Performant GraphQL API for MongoDB With Hasura






Rate this tutorial


In 2012, GraphQL was introduced as a developer-friendly API spec that allows clients to request exactly the data they
need, making it efficient and fast. By reducing the need for multiple requests and limiting the over-fetching of data,
GraphQL simplifies data retrieval, improving the developer experience. This leads to better applications by ensuring
more efficient data loading and less bandwidth usage, particularly important for mobile or low-bandwidth environments.
Using GraphQL — instead of REST — on MongoDB is desirable for many use cases, especially when there is a need to
simultaneously query data from multiple MongoDB instances, or when engineers need to join NoSQL data from MongoDB with
data from another source.
However, engineers are often faced with difficulties in implementing GraphQL APIs and layering them onto their MongoDB
data sources. Often, this learning curve and the maintenance overhead inhibit adoption. Hasura was designed to address
this common challenge with adopting GraphQL.
Hasura is a low-code GraphQL API solution. With Hasura, even engineers unfamiliar with GraphQL can build feature-rich
GraphQL APIs — complete with pagination, filtering, sorting, etc. — on MongoDB and dozens of other data sources in
minutes. Hasura also supports data federation, enabling developers to create a unified GraphQL API across different
databases and services. In this guide, we’ll show you how to quickly connect Hasura to MongoDB and generate a secure,
high-performance GraphQL API.
We will walk you through the steps to:
- Create a project on Hasura Cloud.
- Create a database on MongoDB Atlas.
- Connect Hasura to MongoDB.
- Generate a high-performance GraphQL API instantly.
- Try out GraphQL queries with relationships.
- Analyze query execution.
We will also go over how and why the generated API is highly performant.
At the end of this guide, you’ll be able to create your own high-performance, production-ready GraphQL API with Hasura
for your existing or new MongoDB Atlas instance.
You will need a project on Hasura Cloud and a MongoDB database on Atlas to get started with the next steps.
Head over
to cloud.hasura.io
to create an account or log in. Once you are on the Cloud Dashboard, navigate
to Projects and create a new project by clicking on
New Project.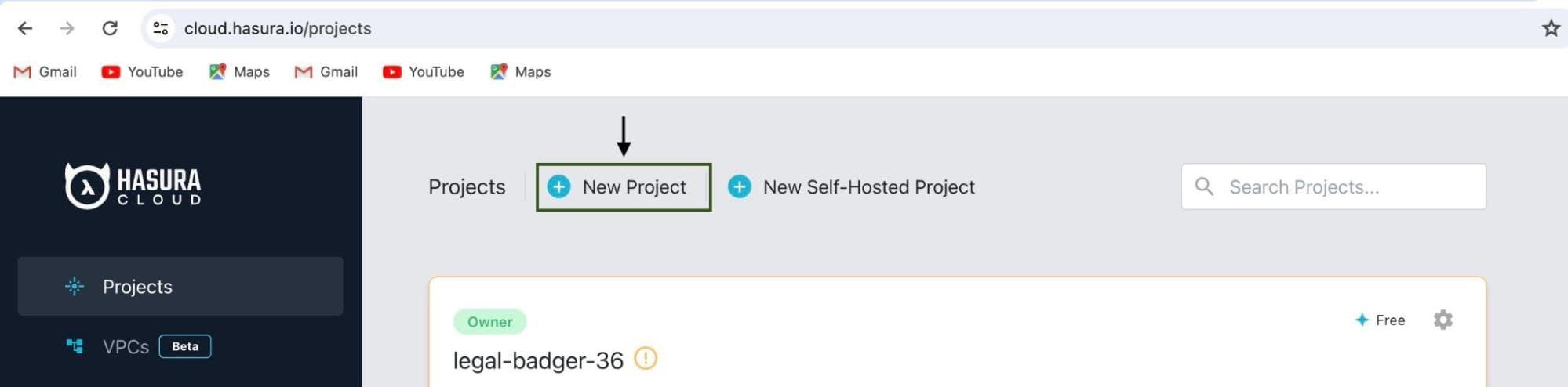
You can create a free project by selecting the region of your choice. In this example, I’m going with AWS
infrastructure, US West region.
Do remember the region picked, because we want to co-locate the GraphQL API deployed using Hasura Cloud in the same
region as the database on MongoDB Atlas. This will be done in one of the subsequent steps. Click on
the
Create Free Project button as highlighted. As always, you can upgrade the project later as required.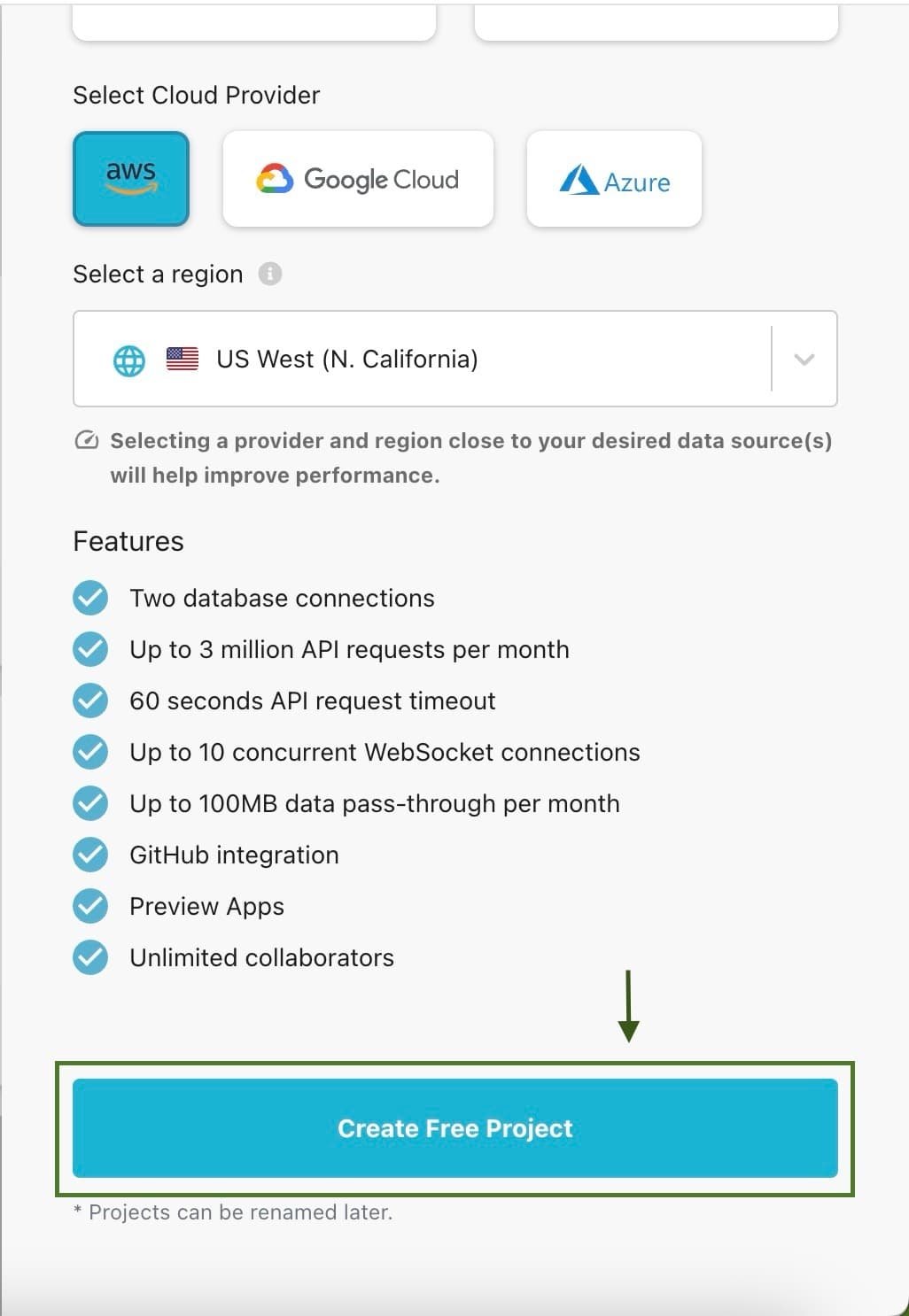
Once the project is created, you’ll be taken to the project details page, which displays the GraphQL endpoint among
other details. Take note of the
Hasura Cloud IP on this page, as it’s required during the MongoDB Atlas setup to allow
the connection from Hasura to MongoDB.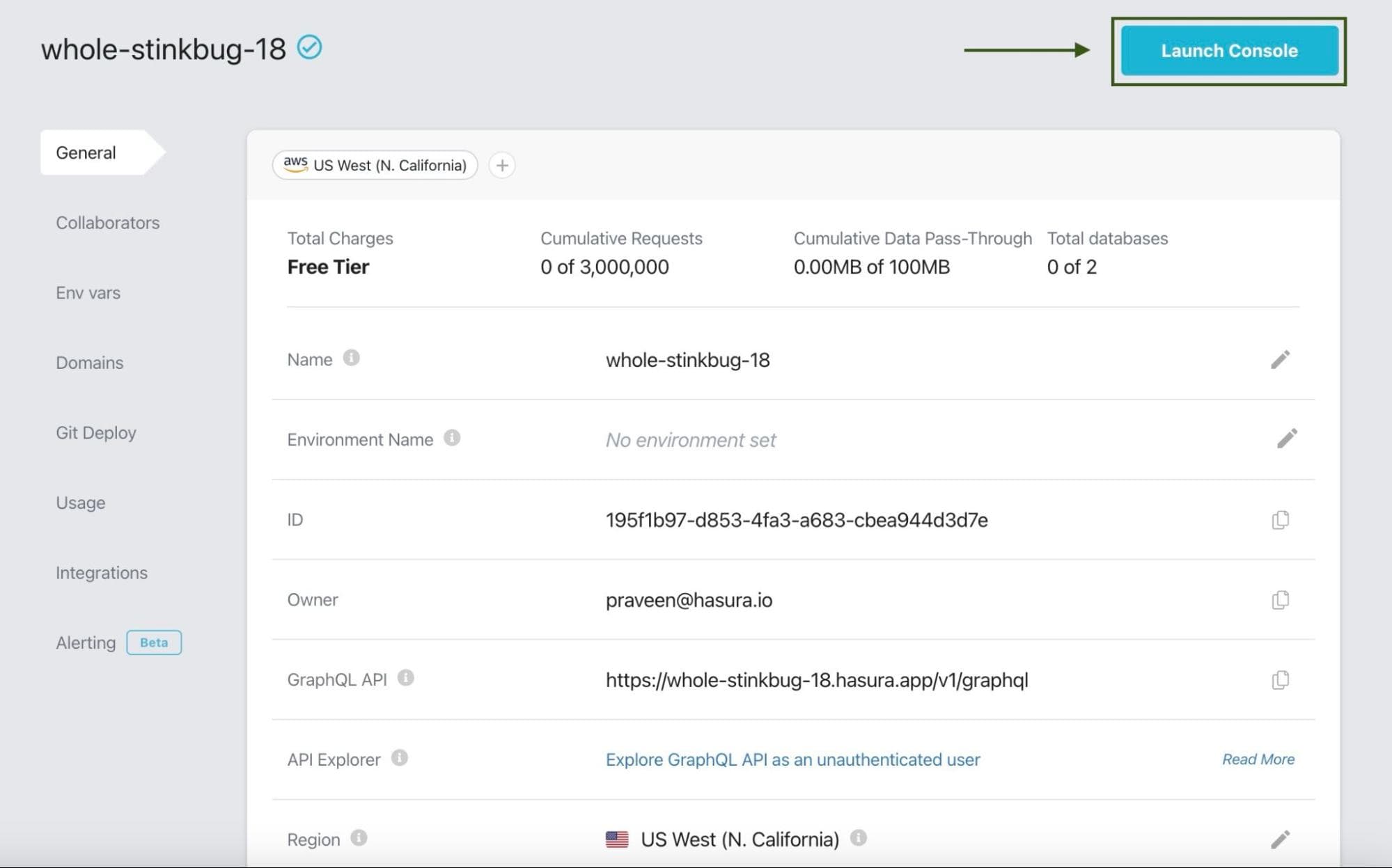
Click on
Launch Console to open up the Hasura Console of the project. You will land on the API Explorer page of the
console where you can try out the GraphQL APIs.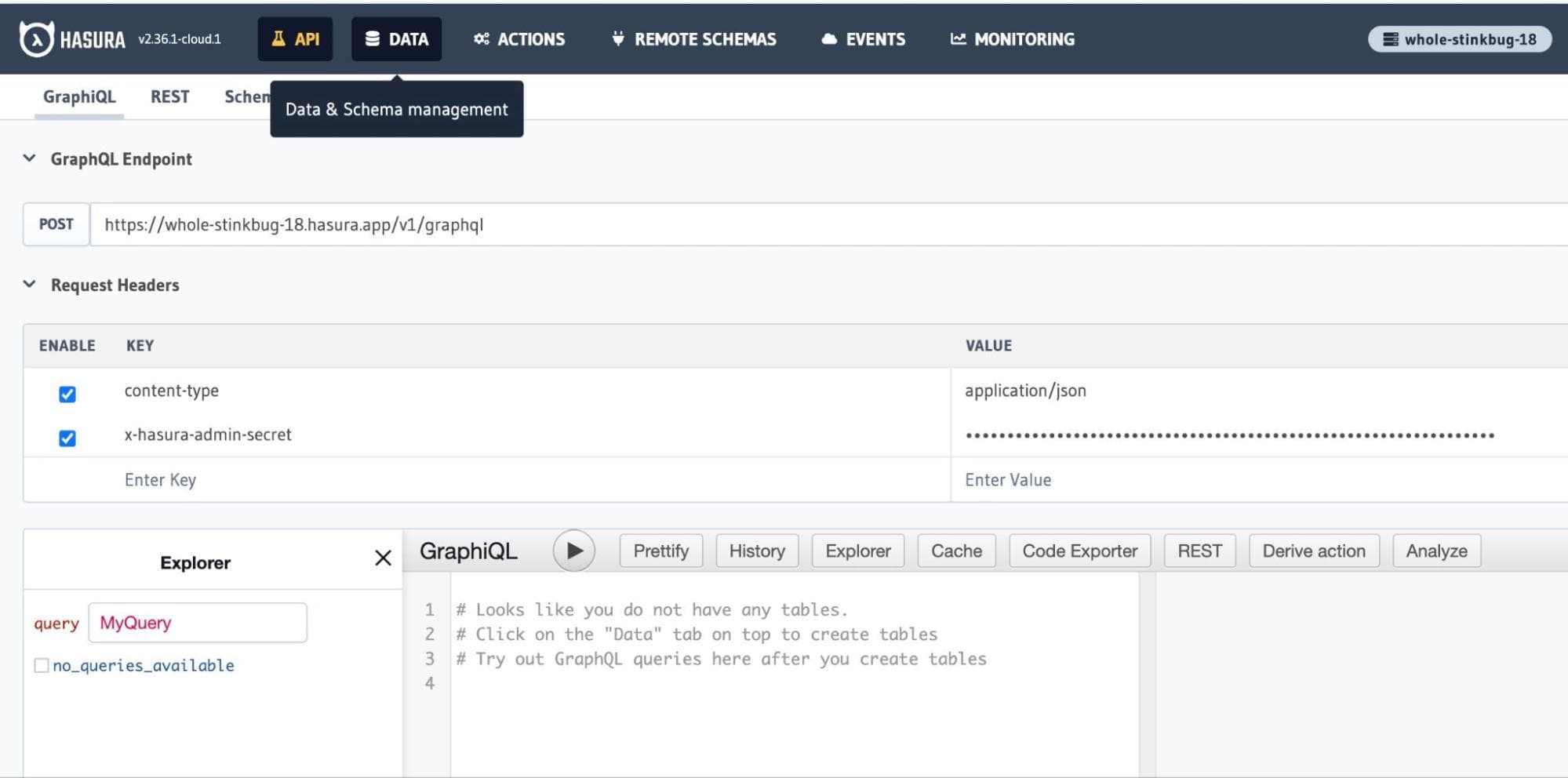
Click on the
DATA tab at the top to navigate to the Data Management section of the console. Here you can connect to
the various databases that Hasura supports. Choose MongoDB from the list and click on Connect Existing Database.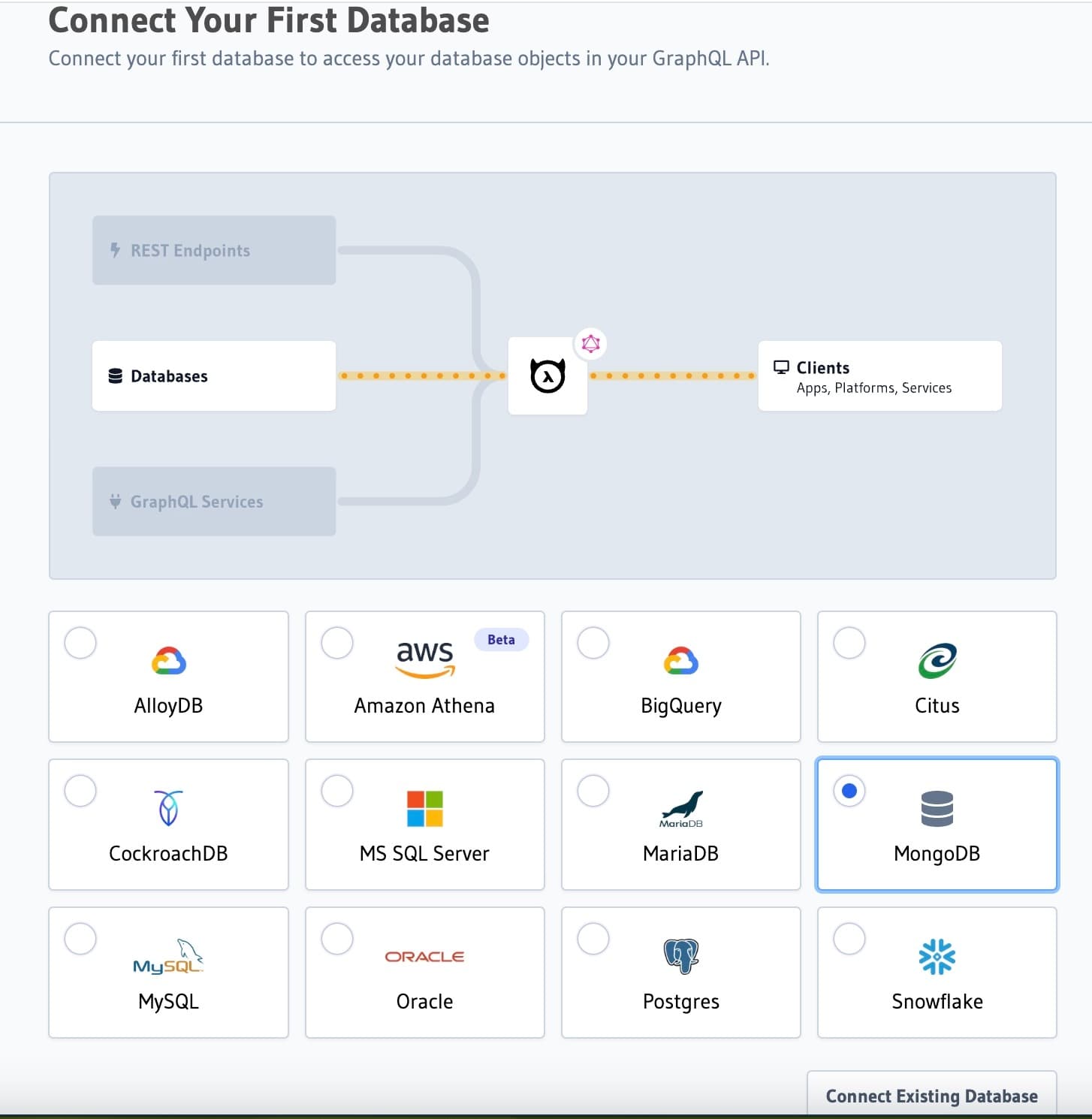
At this point, Hasura requires the connection details of MongoDB.
If you already have an existing MongoDB instance, feel free to try out the demo with that.
For this tutorial, first create a new MongoDB instance. But you can skip this step if you already have a database.
Hasura can connect to a new or an existing MongoDB Atlas database and generate the GraphQL API for you. Now, go ahead
and create a new database and use some autogenerated sample data.
Head to MongoDB Atlas, create a project if you don’t have one, and navigate to
the
Database page under the
Deployments section. You should see a page like the one below: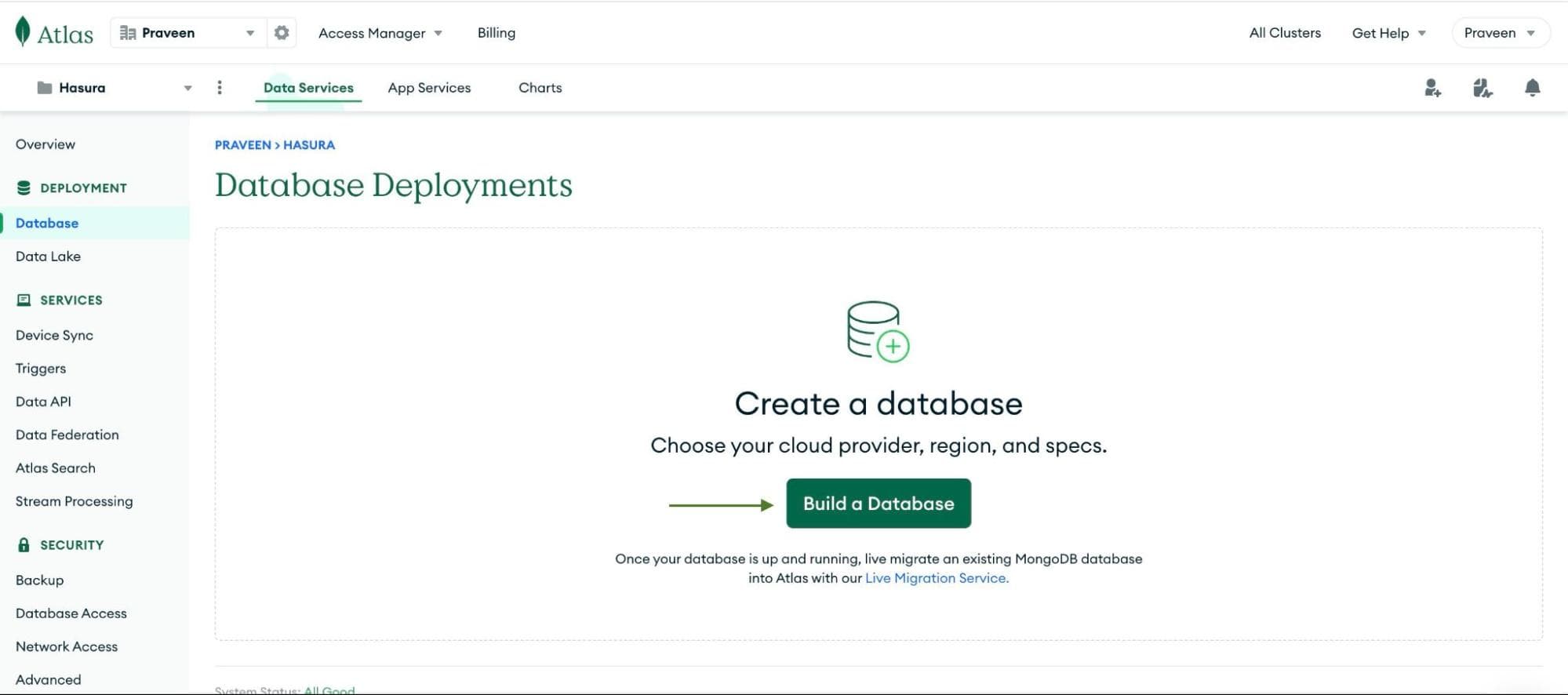
Click on the
Build a Database button. On the next page, you will select the deployment specifics.To keep it simple, start with the Free M0 cluster, which is free forever and great for getting started. You can always
upgrade later when required.
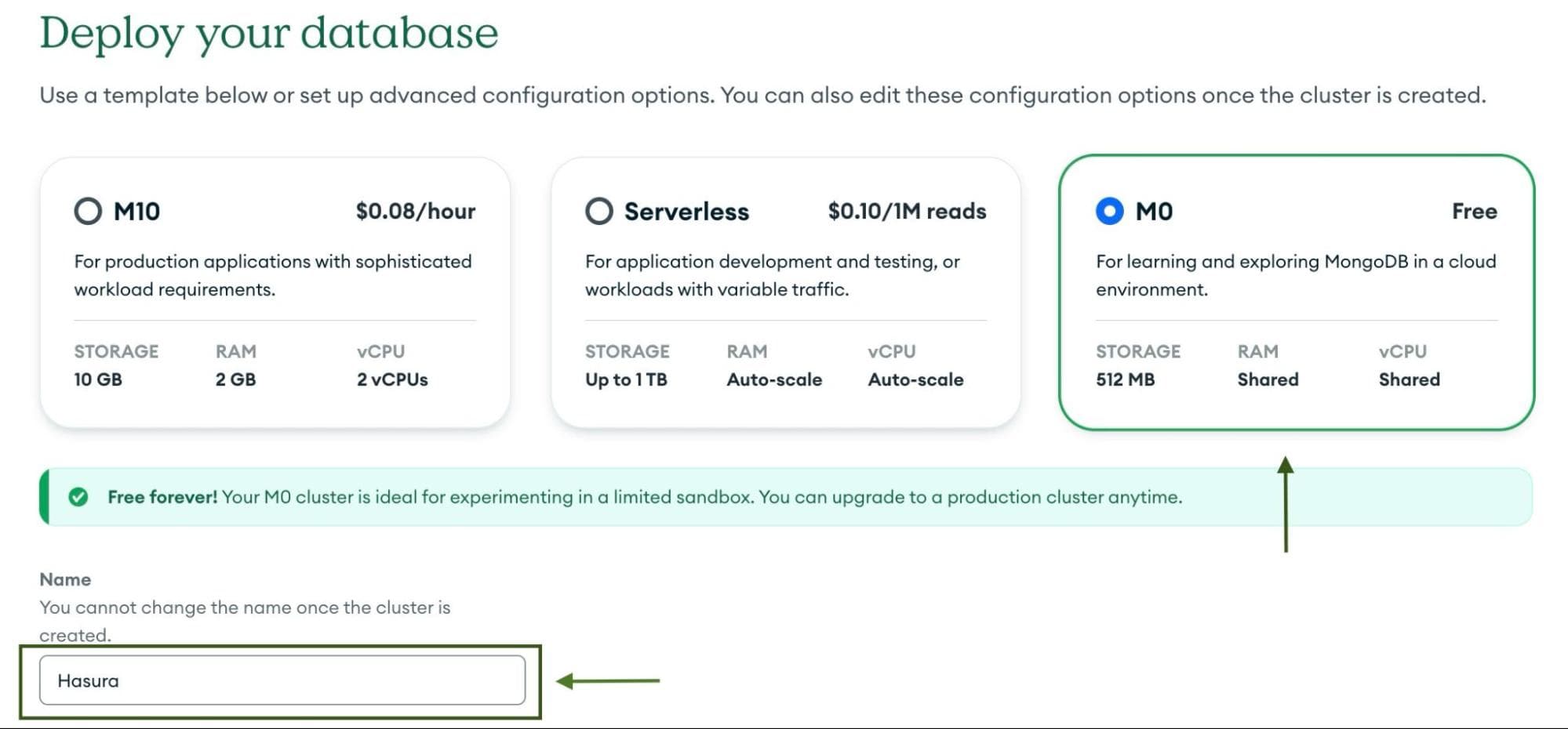
Give a name for the cluster; for this example, use
Hasura. You will need to select the region. For this tutorial, pick
AWS as the provider and choose the us-west-2 region to keep the data close to the Hasura instance (recall that our
Hasura cluster was deployed on US West, as well).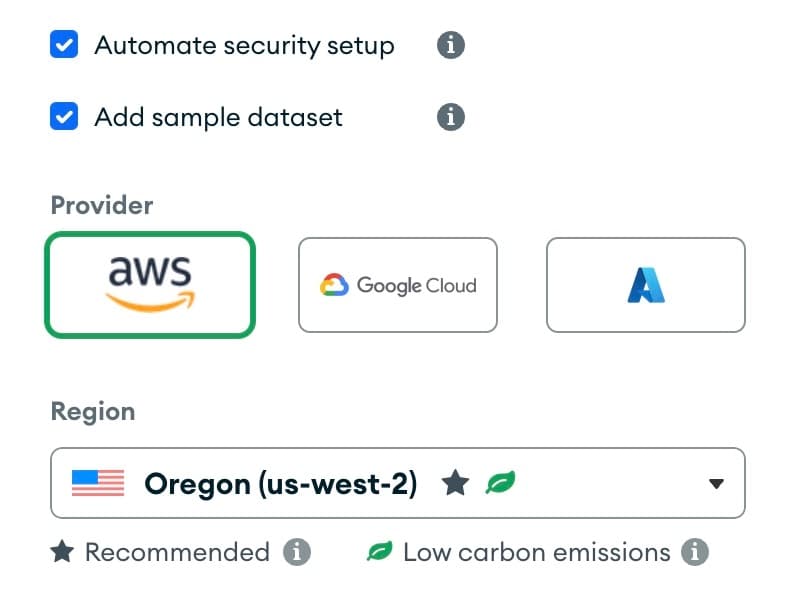
Remember to choose the region closest to your users.
Tip: It is recommended to keep your database and API region the same to avoid performance and latency issues.
In the next step, add your IP address for local connectivity and create a new database user with
atlasAdmin permission
that you’ll need to access the MongoDB cluster from Hasura Cloud.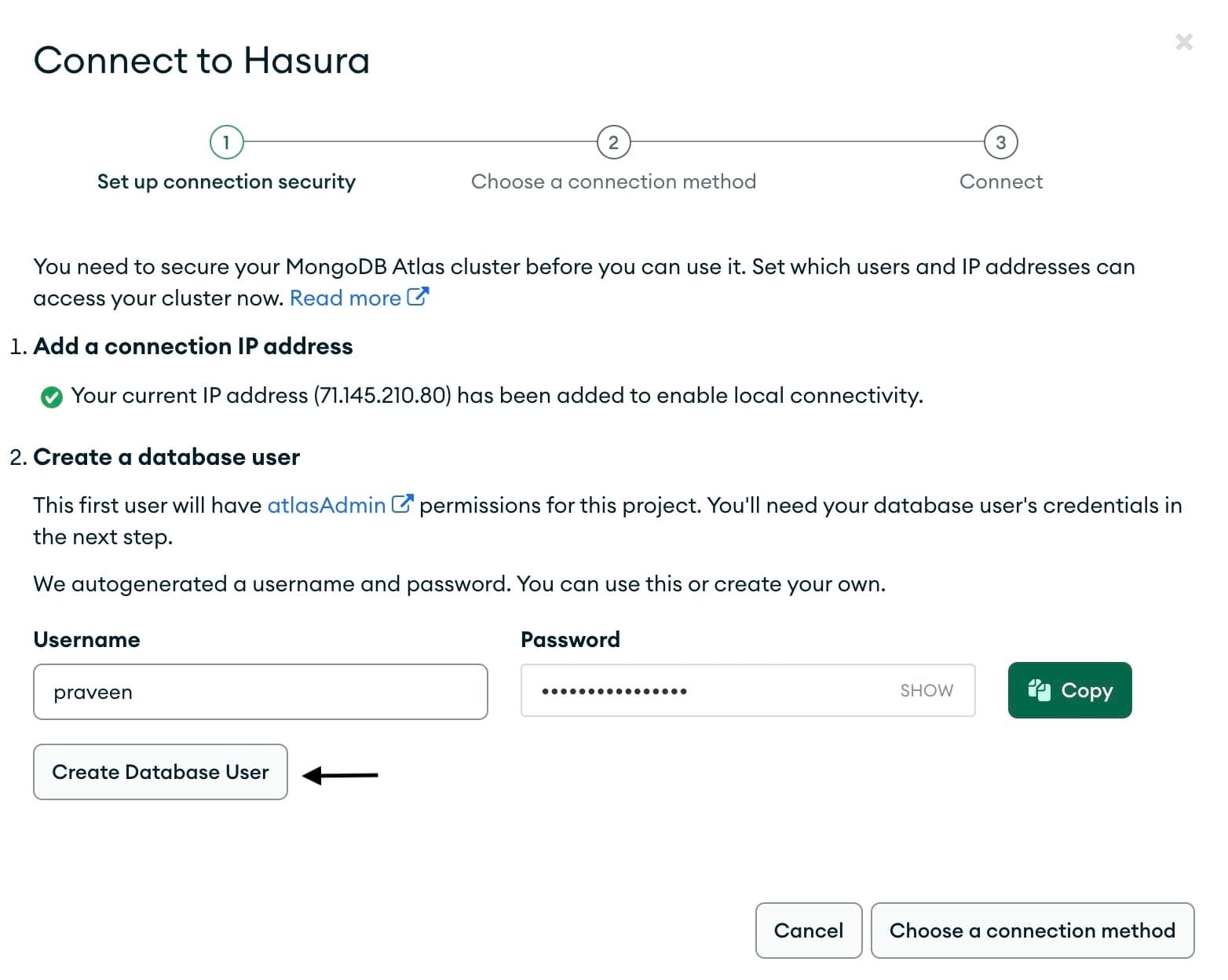
Make a note of the password, because we need this in a later step.
Now, click on
Create Database User. Click on Choose a connection method and skip the next steps.Optionally, you can refer to the instructions
for creating a new MongoDB database deployment
in the docs, particularly until Step 4, in case you are stuck in any of the steps above.
Once the database deployment is complete, you might want to load some sample data for the cluster. You can do this by
heading to the
Database tab and under the newly created Cluster, click on the ... that opens up with an option
to Load Sample Dataset. This can take a few seconds.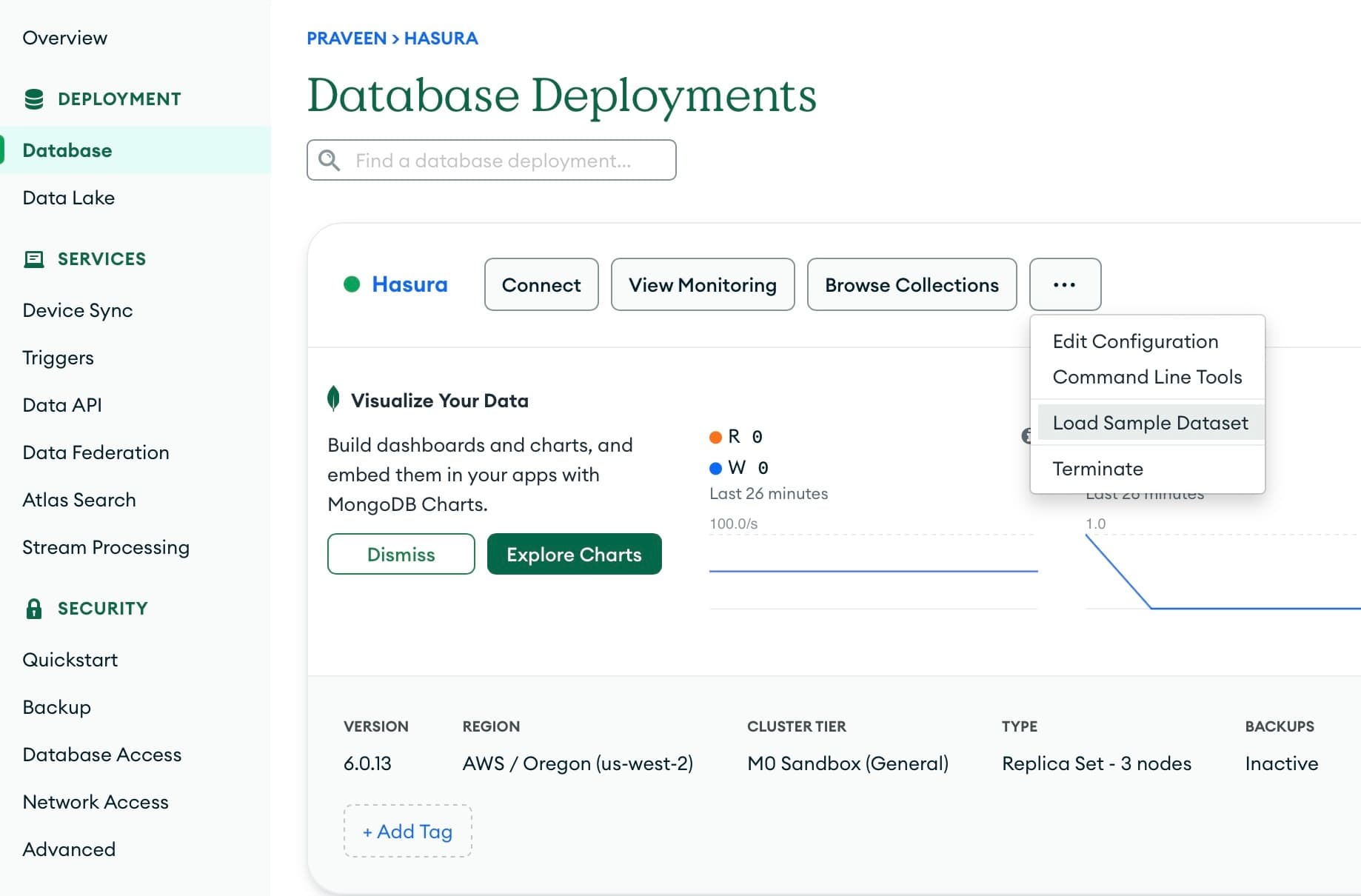
Checkpoint: At this stage, we have created a project on Hasura Cloud and a database on MongoDB Atlas.
To connect Hasura to MongoDB, first add the Hasura Cloud IP address to your MongoDB cluster. To do that, navigate to the
Network Access page (under Security) from the Atlas dashboard.
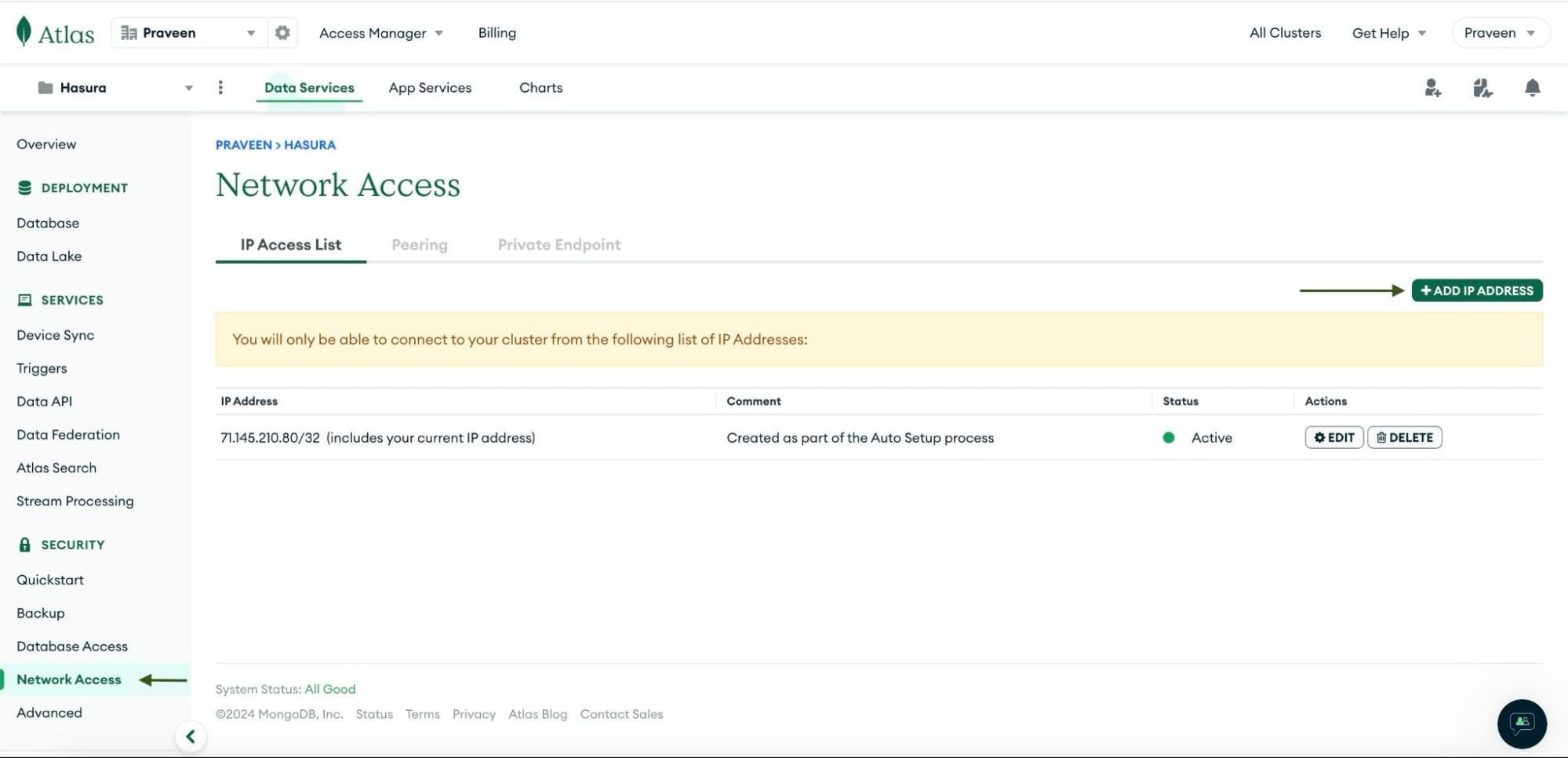
Click on
ADD IP ADDRESS and enter the Hasura Cloud IP that you obtained from the Hasura Cloud dashboard in the first
step.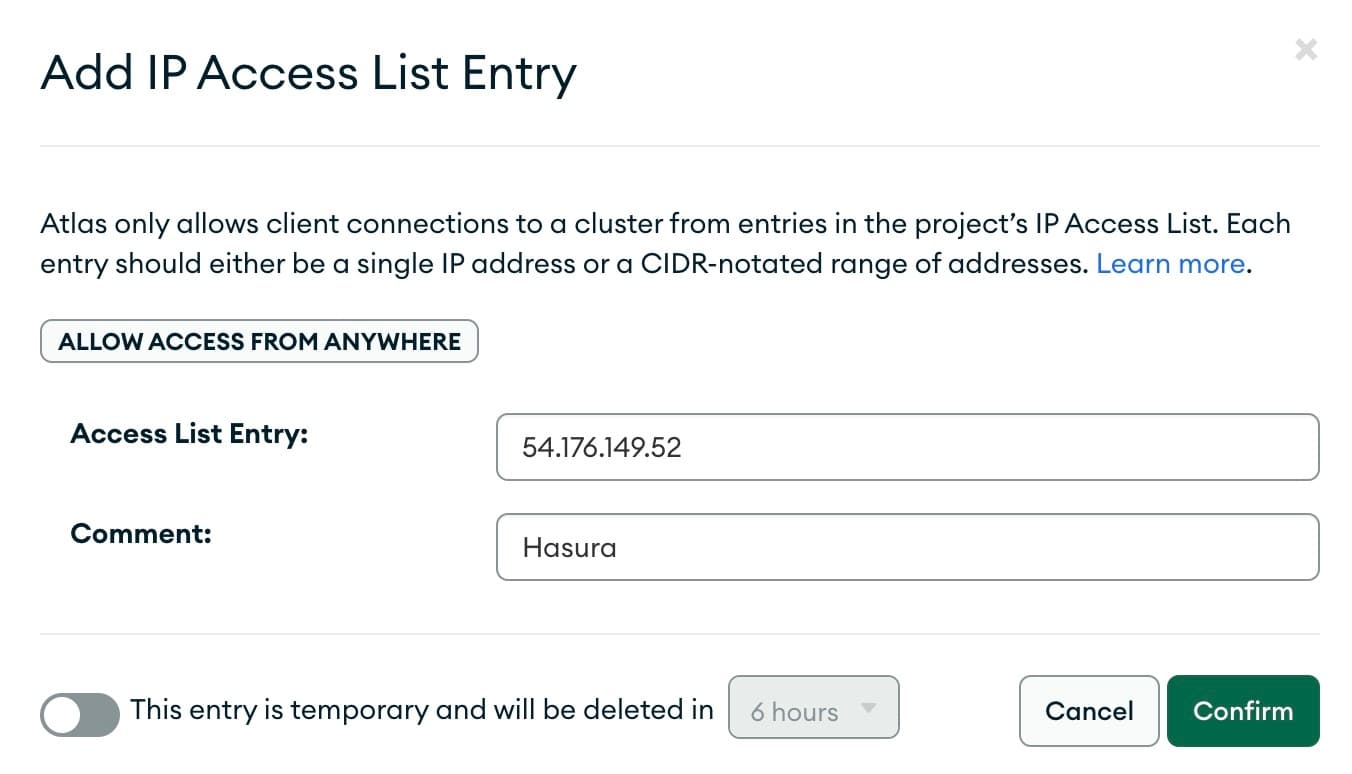
Once this is done, Hasura Cloud should be able to communicate with the MongoDB Atlas instance. The next step is to get
the database connection string.
On the Atlas dashboard, head to the
Database page and click on Connect next to the Hasura cluster created some steps
back. You’ll get the following options — choose the Drivers option.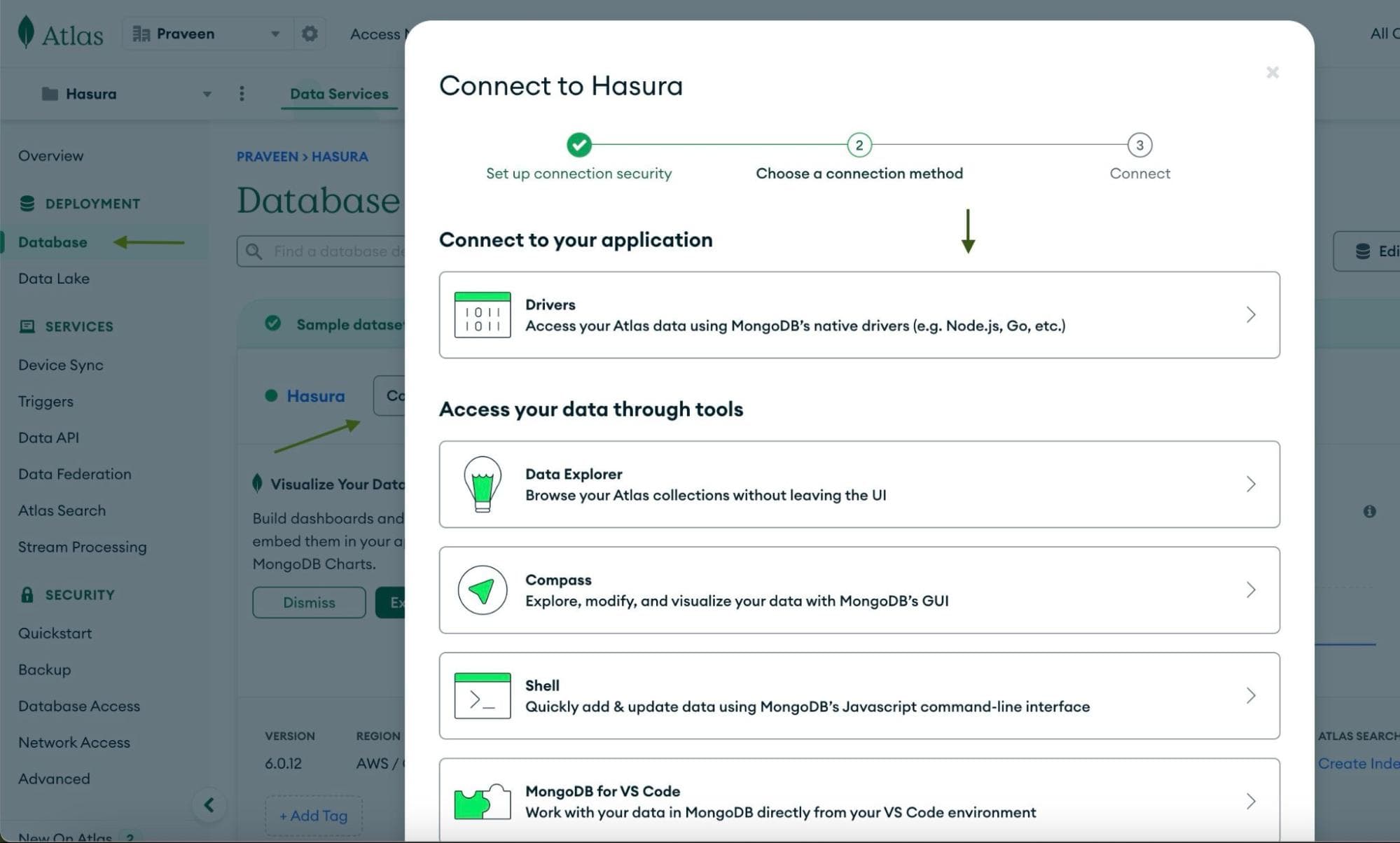
You will get a popup with the connection string details. Copy the connection string for the database, which will be
similar to this format:

Note that you need to replace
<password> with the actual password of the database user that you created earlier.You can access the Database Users from the Database Access tab under the Security section of the left navigation menu.
Remember that the database user needs to have
atlasAdmin permission for the connection to work.Now, move on to the Hasura Cloud dashboard for the next step.
As you are on the Connect Existing Database for MongoDB page, enter the values for the name of the database
as
mongodb, the connection string copied from the previous step.This instance comes with a sample database called
sample_mflix. Enter that under the db config.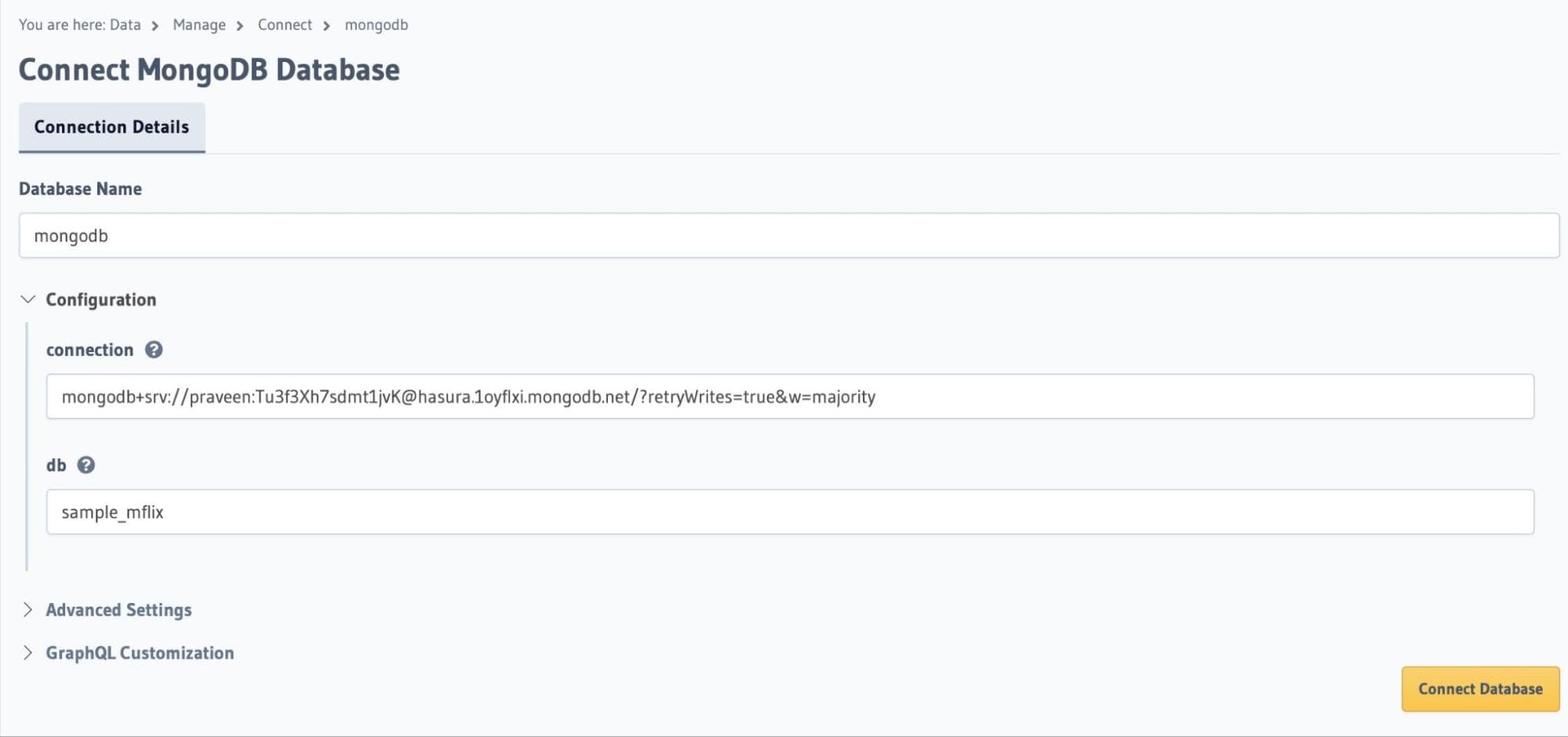
Finally, click on
Connect Database and you are all set with the connection of Hasura and MongoDB, all hosted on their
respective Cloud instances.This is the exciting part of the guide. 😀
For the sample database that was loaded to MongoDB, you can generate an API instantly.
Head over to the mongodb -> Manage page on Hasura Console.
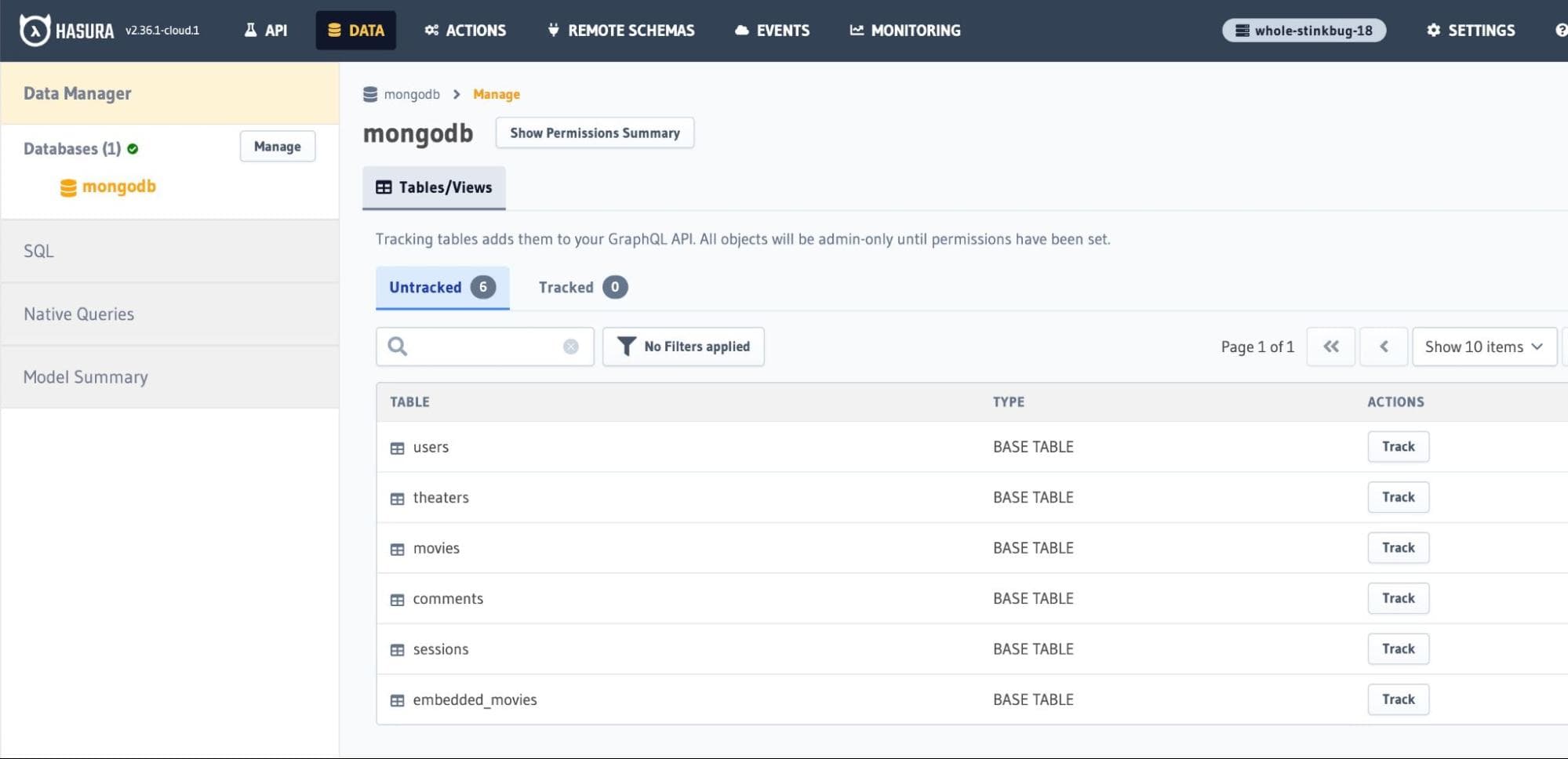
Check out the collections from the sample database shown on this page. For example, you can see collections such
as
users, theaters, movies, comments, sessions, and embedded_movies. Now you can Track them to make sure
Hasura generates the GraphQL (and REST) API for the collections.Start by tracking the
movies collection. Click on the Track button next to the movies collection.In this step, you’ll need to indicate to Hasura what the structure of the JSON object is so that Hasura can introspect
and generate a GraphQL schema for this.
Insert the following JSON as input:
Alternatively, if you want to copy these objects from your Mongo collections directly, head to the
Collections tab
under the Database section.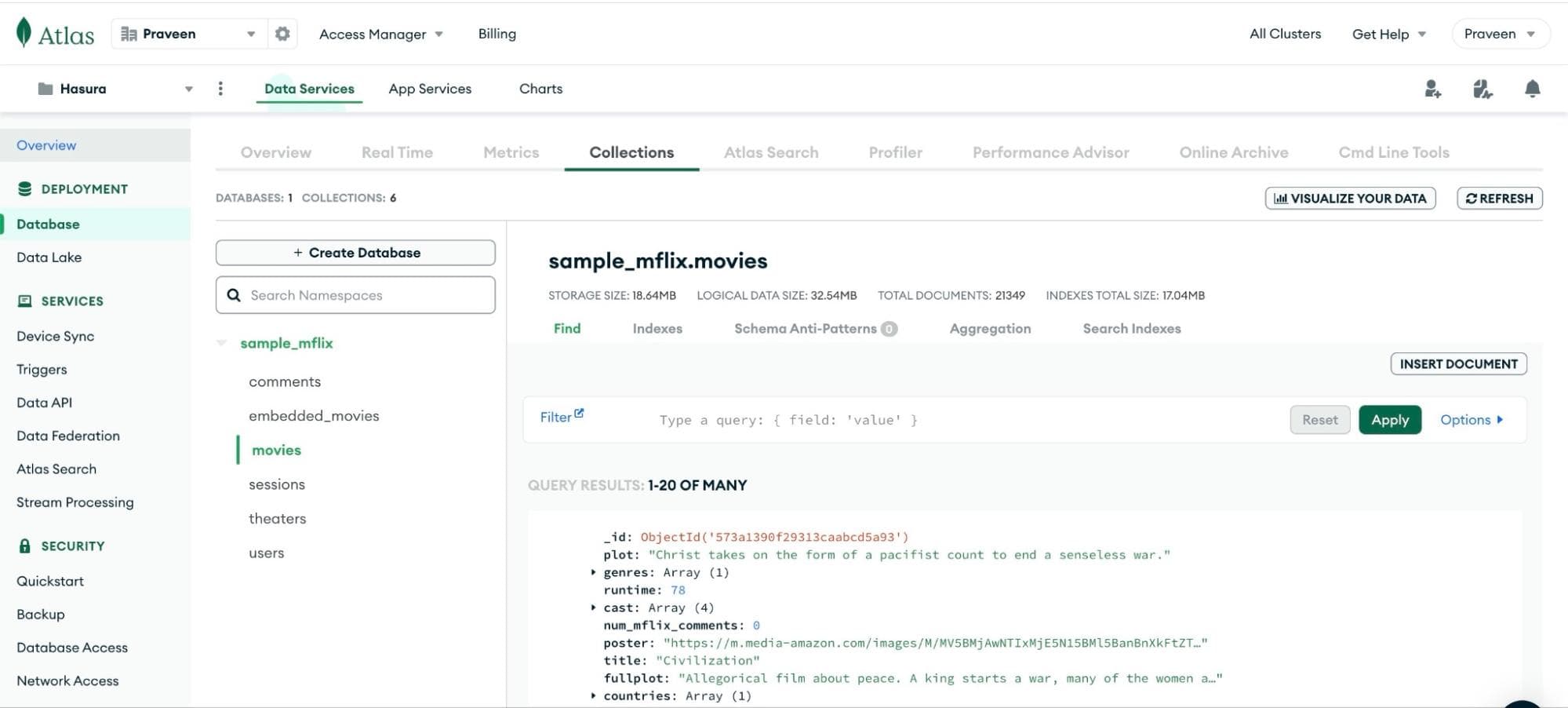
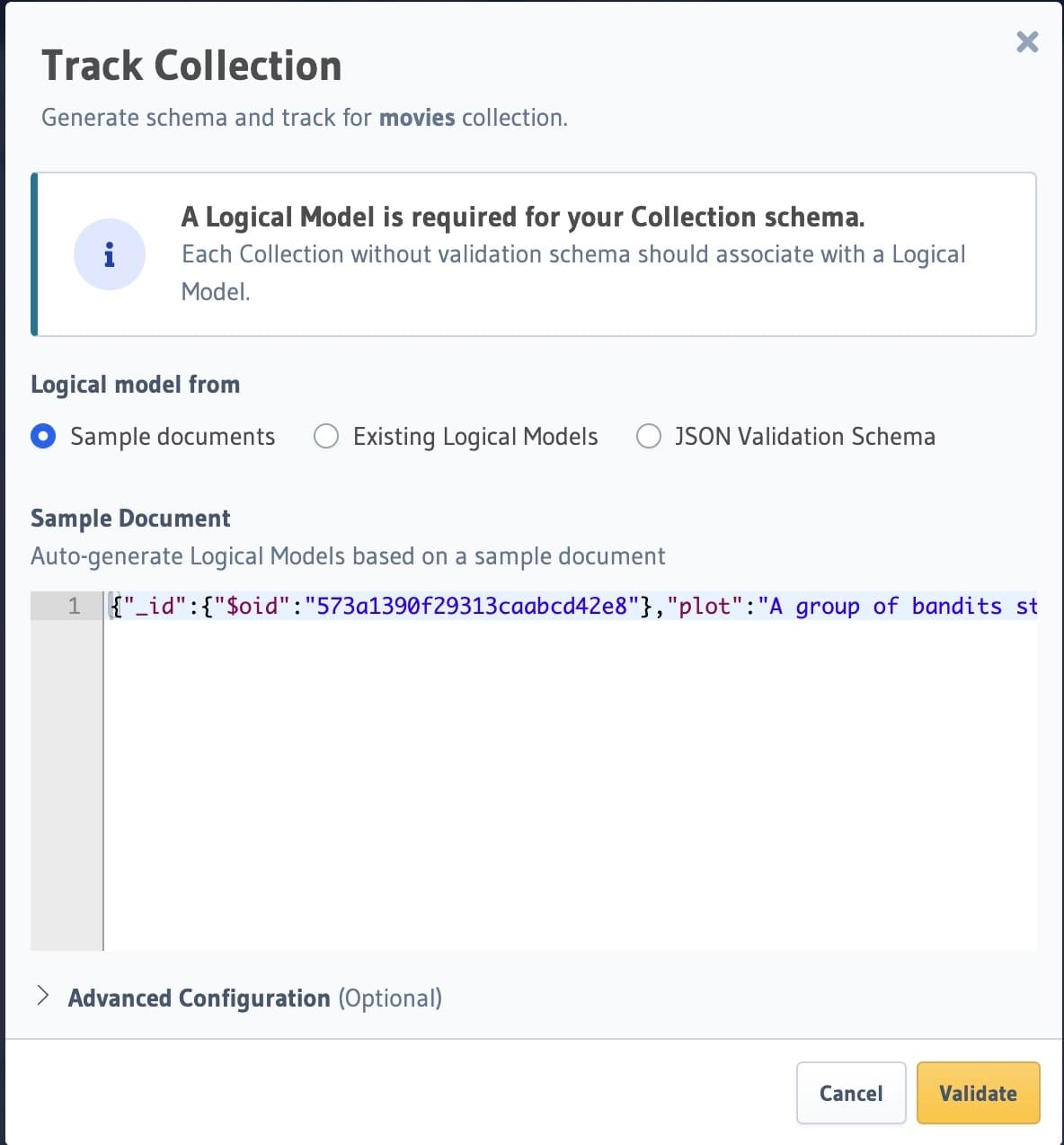
Click on the
Validate button to validate the JSON document. In the next step, you will see the models derived from
this document. Finally, click on the Track Collection button.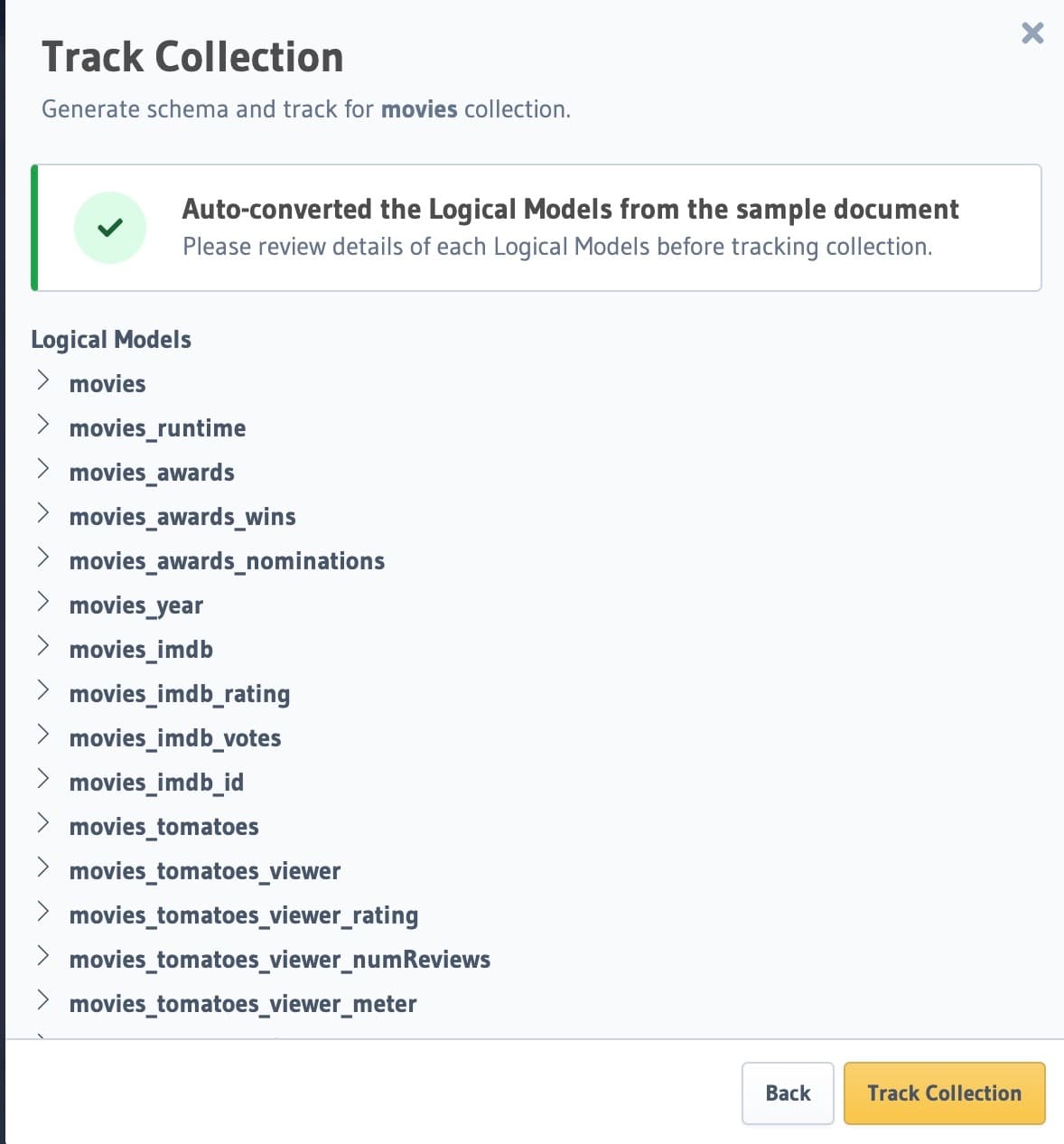
Once you track the collection, you should navigate to the API Explorer page on the Hasura Console to start trying out
some GraphQL queries.
Execute the following GraphQL query inside the GraphiQL interface.
We are trying to fetch 10 movies, sorted by released, descending.
You will get a JSON response on the right as you execute the query by clicking the
play button.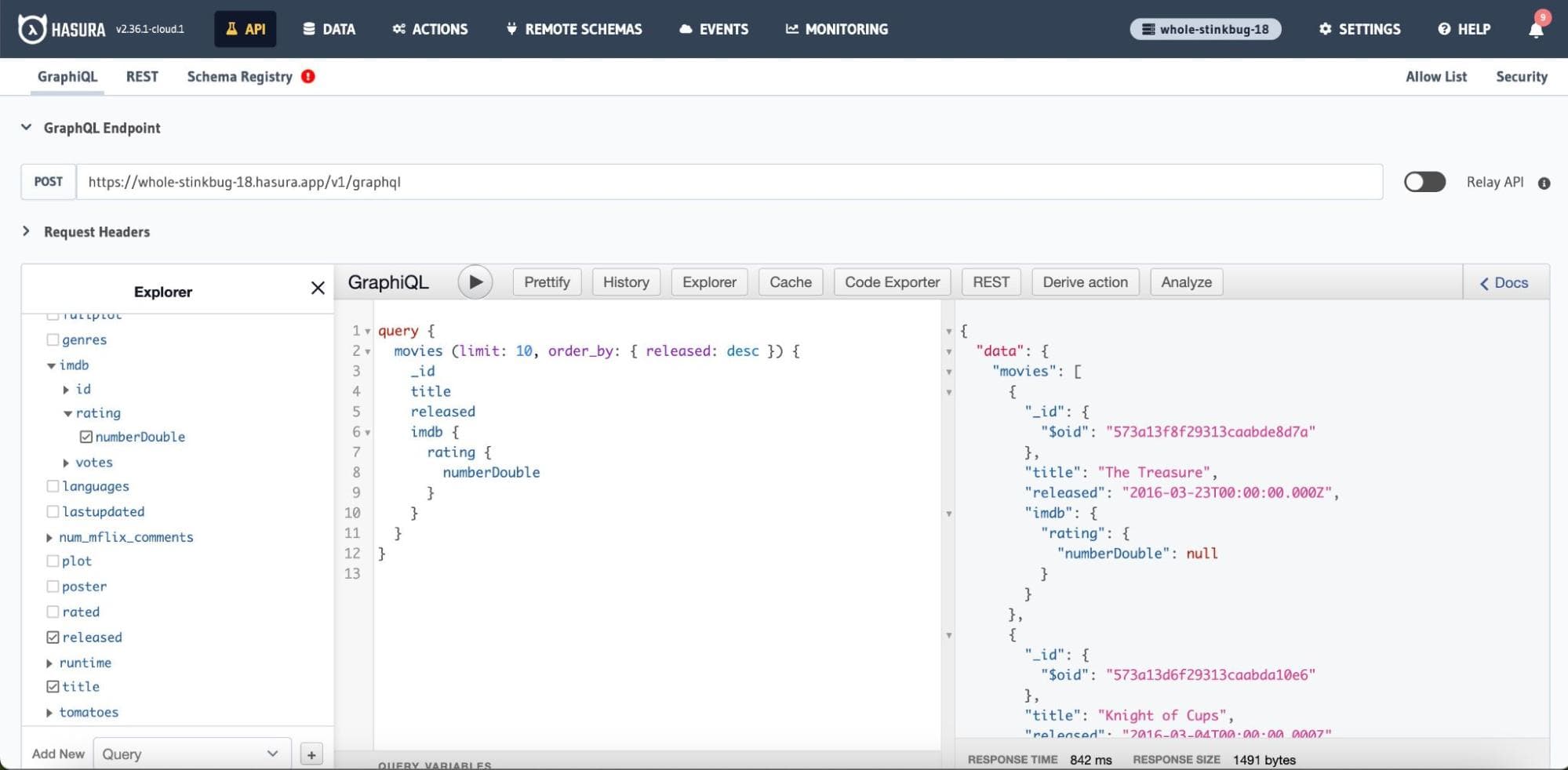
Voilà! GraphQL API for the
movies collection is now tested and ready for consumption.Do play around with different queries as you see them on the
Explorer tab on the left sidebar.You can repeat this for tracking more collections like
comments, users, theaters, etc., and get APIs generated for
all of them.The fact that Hasura has generated the GraphQL API instantly for the collections reduces a lot of boilerplate code that
you would have otherwise written in the form of GraphQL resolvers in any server.
Now, you might be curious about the API performance. You have already ensured that the database and the API are in the
same region to avoid latency issues. But let’s dive deeper into how the query execution works behind the scenes.
It essentially boils down to these factors:
- Database pushdowns
- Query compilation that uses aggregate pipelines
Hasura is a compiler that takes in a GraphQL query, enriches it with predicates as part of the query, and pushes down
the query with projection, relationships, and authorization rules to the database to handle the workload. This avoids
server-side processing of data and leverages the database capabilities to be highly efficient and performant.
With the nature of GraphQL allowing the client to query what they want, it’s essential to only fetch the exact fields
requested by the client. Hasura does this by compiling the query with projection. Without Hasura, a typical query might
be unoptimized and would fetch unnecessary data (more data than required).
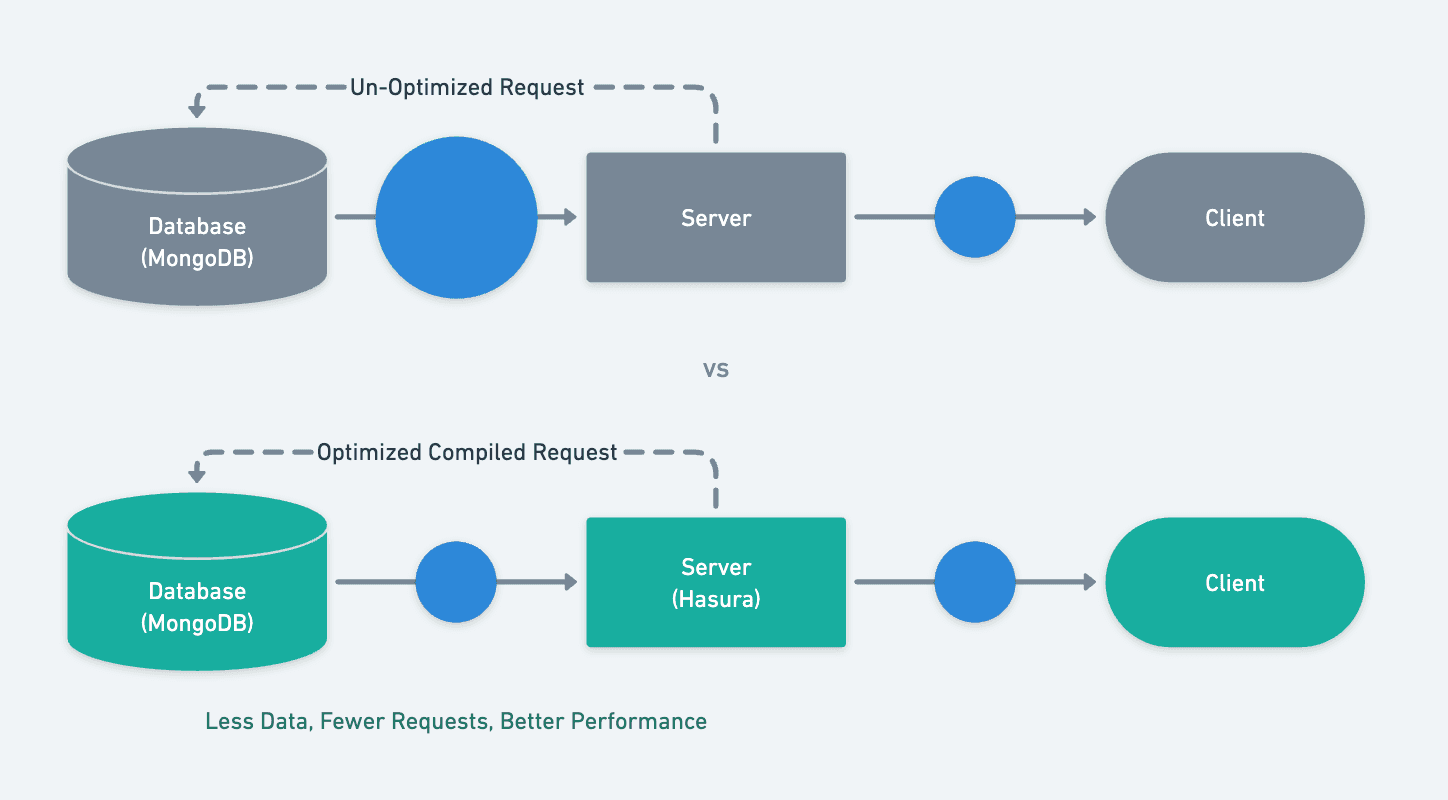
Let’s analyze the query that is generated by Hasura. For the example GraphQL query that we used above, click on
the
Analyze button on the GraphiQL section of the API Explorer page.You’ll see that the query execution plan looks like this:
As the structure of a document in a collection changes, it should be as simple as updating the Hasura metadata to add or
remove the modified fields. The schema is flexible, and you can update the logical model to get the API updates. There
are no database migrations required — just add or remove fields from the metadata to reflect in the API.
The integration of MongoDB with Hasura’s GraphQL Engine brings a new level of efficiency and scalability to developers.
By leveraging Hasura’s ability to create a unified GraphQL API from diverse data sources, developers can quickly expose
MongoDB data over a secure, performant, and highly customizable GraphQL API.
We recommend a few resources to learn more about the integration.
Join the Hasura Discord server to engage with the Hasura community, and ask questions about
GraphQL or Hasura’s integration with MongoDB.
Top Comments in Forums
There are no comments on this article yet.