How to Archive Data to Cloud Object Storage with MongoDB Online Archive

Maxime Beugnet9 min read • Published Feb 07, 2022 • Updated May 31, 2023





Rate this tutorial


MongoDB Atlas Online Archive is a new feature of the MongoDB Cloud Data Platform. It allows you to set a rule to automatically archive data off of your Atlas cluster to fully-managed cloud object storage. In this blog post, I'll demonstrate how you can use Online Archive to tier your data for a cost-effective data management strategy.
The MongoDB Cloud data platform with Atlas Data Federation provides a serverless and scalable Federated Database Instance which allows you to natively query your data across cloud object storage and MongoDB Atlas clusters in-place.
In this blog post, I will use one of the MongoDB Open Data COVID-19 time series collections to demonstrate how you can combine Online Archive and Atlas Data Federation to save on storage costs while retaining easy access to query all of your data.
For this tutorial, you will need:
- a MongoDB Atlas M10 cluster or higher as Online Archive is currently not available for the shared tiers,
To begin with, let's retrieve a time series collection. For this tutorial, I will use one of the time series collections that I built for the MongoDB Open Data COVID19 project.
The
covid19.global_and_us collection is the most complete COVID-19 times series in our open data cluster as it combines all the data that JHU keeps into separated CSV files.As I would like to retrieve the entire collection and its indexes, I will use
mongodump.
This will create a
dump folder in your current directory. Let's now import this collection in our cluster.Now that our time series collection is here, let's see what a document looks like:
This time series collection is fairly simple. For each day and each place, we have a measurement of the number of
confirmed, deaths and recovered if it's available. More details in our documentation.Problem is, it's a time series! So each day, we add a new entry for each place in the world and our collection will get bigger and bigger every single day. But as time goes on, it's likely that the older data is less important and less frequently accessed so we could benefit from archiving it off of our Atlas cluster.
Today, July 10th 2020, this collection contains 599760 documents which correspond to 3528 places, time 170 days and it's only 181.5 MB thanks to WiredTiger compression algorithm.
While this would not really be an issue with this trivial example, it will definitely force you to upgrade your MongoDB Atlas cluster to a higher tier if an extra GB of data was going in your cluster each day.
Upgrading to a higher tier would cost more money and maybe you don't need to keep all this cold data in your cluster.
It works, but you will need to extract and remove the documents from your MongoDB Atlas cluster yourself and then use the new $out operator or the s3.PutObject MongoDB Realm function to write your documents to cloud object storage - Amazon S3 or Microsoft Azure Blob Storage.
Lucky for you, MongoDB Atlas Online Archive does this for you automatically!
Let's head to MongoDB Atlas and click on our cluster to access our cluster details. Currently, Online Archive is not set up on this cluster.

Now let's click on Online Archive then Configure Online Archive.
The next page will give you some information and documentation about MongoDB Atlas Online Archive and in the next step you will have to configure your archiving rule.
In our case, it will look like this:
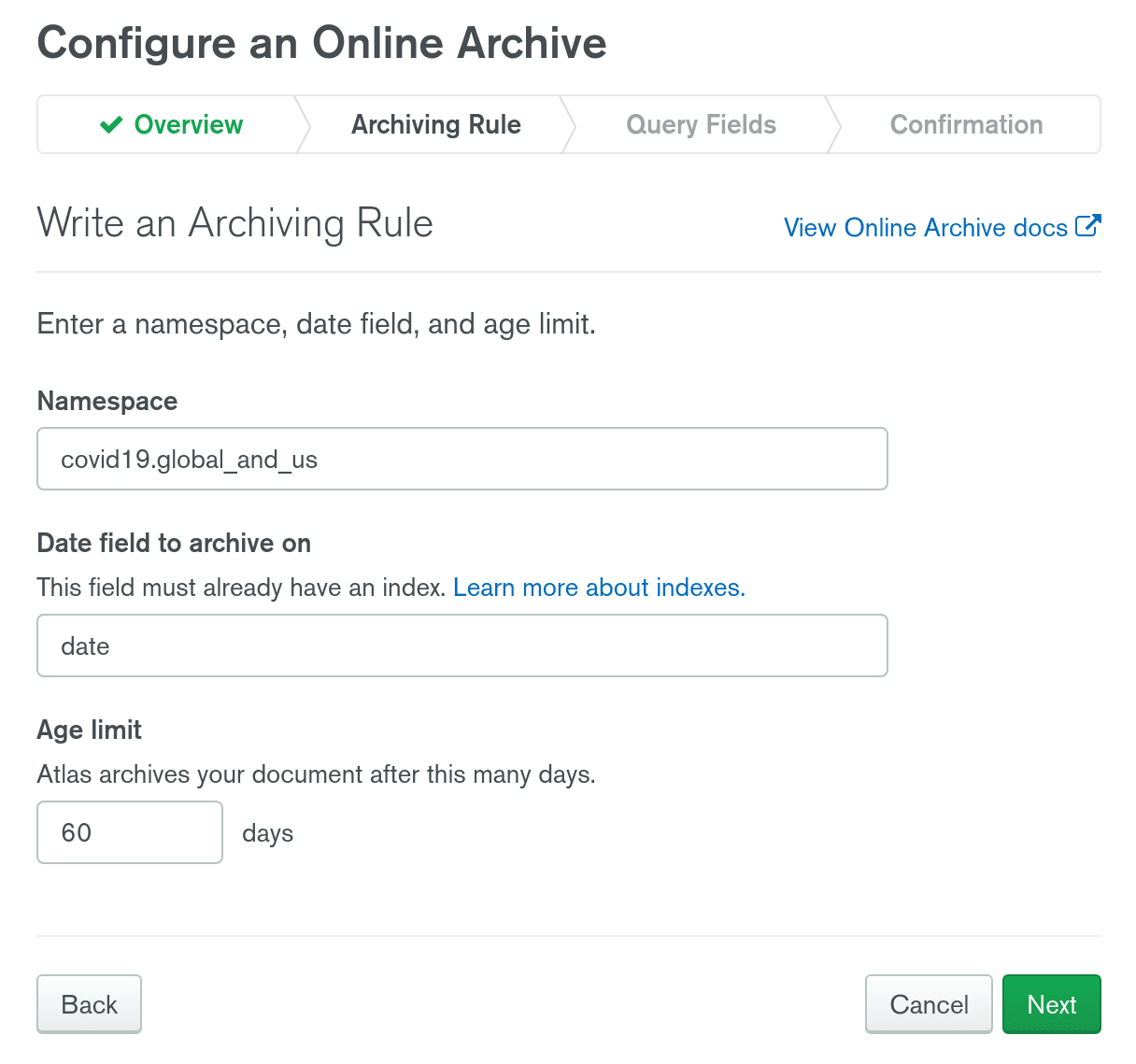
As you can see, I'm using the date field I mentioned above and if this document is more than 60 days old, it will be automatically moved to my cloud object storage for me.
Now, for the next step, I need to think about my access pattern. Currently, I'm using this dataset to create awesome COVID-19 charts.
And each time, I have to first filter by date to reduce the size of my chart and then optionally I filter by country then state if I want to zoom on a particular country or region.
As these fields will convert into folder names into my cloud object storage, they need to exist in all the documents. It's not the case for the field "state" because some countries don't have sub-divisions in this dataset.

As the date is always my first filter, I make sure it's at the top. Folders will be named and organised this way in my cloud object storage and folders that don't need to be explored will be eliminated automatically to speed up the data retrieval process.
Finally, before starting the archiving process, there is a final step: making sure Online Archive can efficiently find and remove the documents that need to be archived.
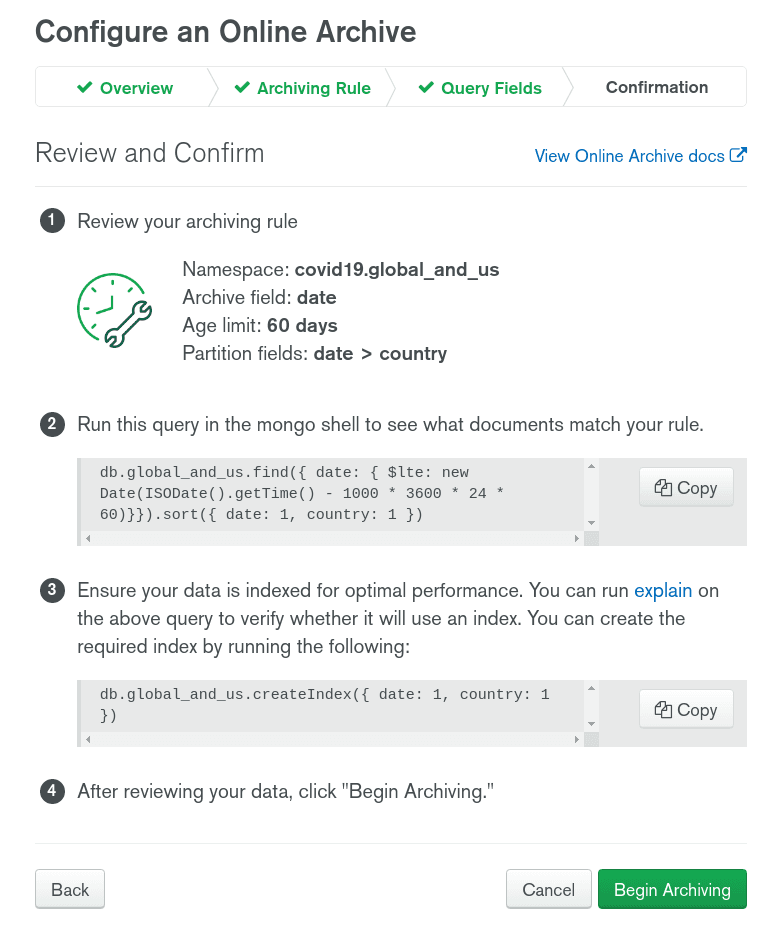
I already have a few indexes on this collection, let's see if this is really needed. Here are the current indexes:
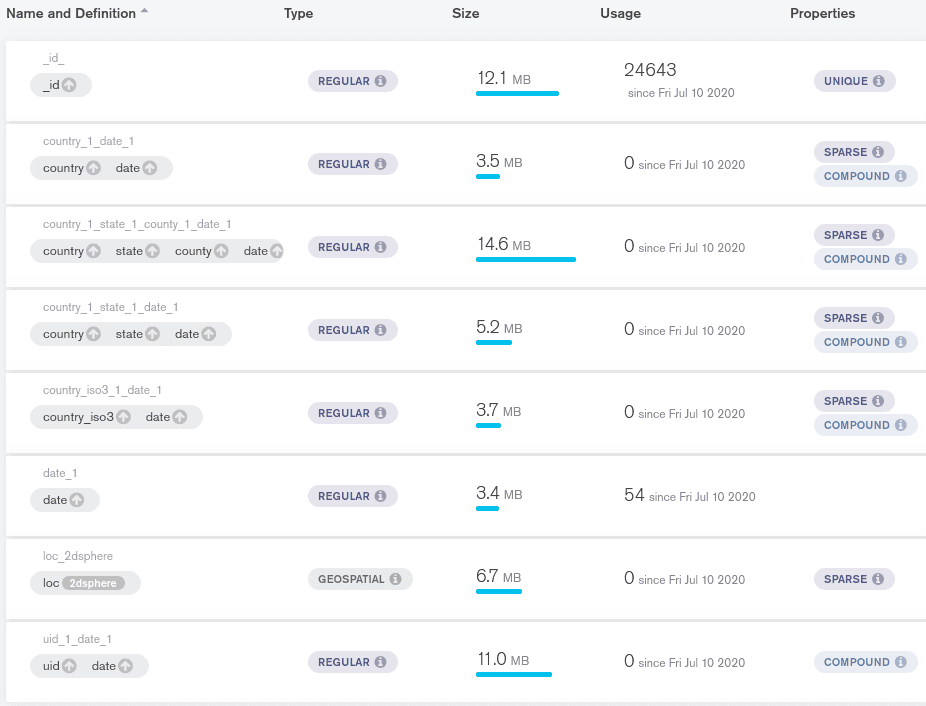
As we can see, I don't have the recommended index. I have its opposite:
{country: 1, date: 1} but they are not equivalent. Let's see how this query behaves in MongoDB Compass.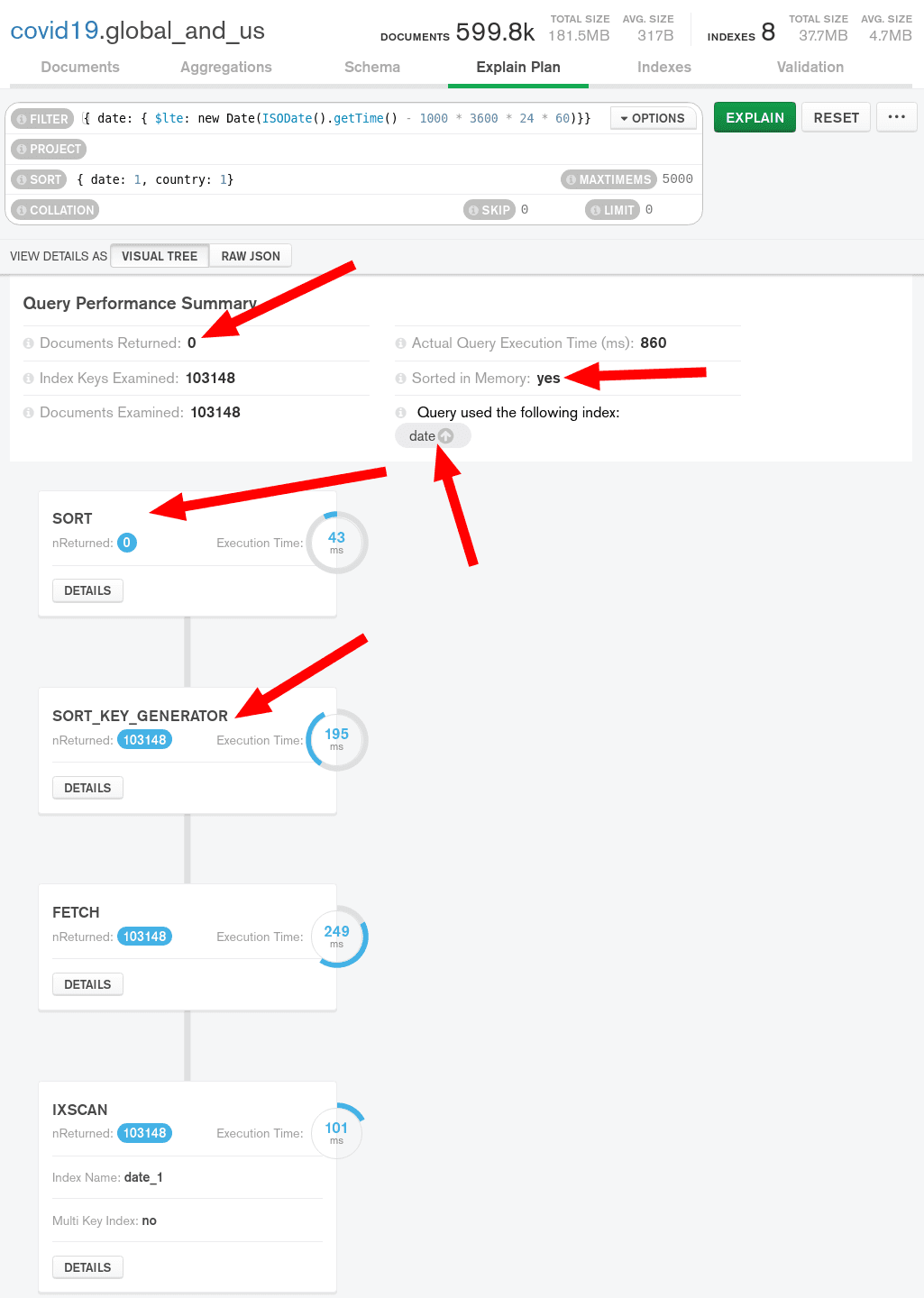
We can note several things in here:
- We are using the date index. Which is a good news, at least it's not a collection scan!
- The final sort operation is
{ date: 1, country: 1} - Our index
{date:1}doesn't contain the information about country so an in-memory sort is required. - Wait a minute... Why do I have 0 documents returned?!
I have 170 days of data. I'm filtering all the documents older than 60 days so I should match
3528 places * 111 days = 391608 documents.111 days (not 170-60=110) because we are July 10th when I'm writing this
and I don't have today's data yet.
When I check the raw json output in Compass, I actually see that an
error has occurred.
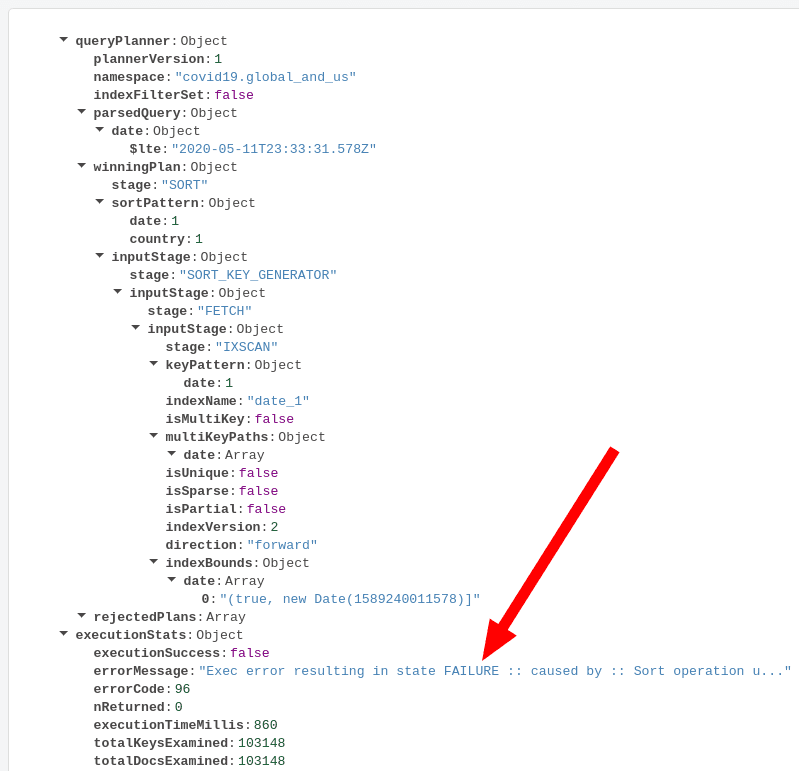
I ran out of RAM...oops! I have a few other collections in my cluster
and the 2GB of RAM of my M10 cluster are almost maxed out.
In-memory
sorts
actually use a lot of RAM and if you can avoid these, I would definitely
recommend that you get rid of them. They are forcing some data from your
working set out of your cache and that will result in cache pressure and
more IOPS.
Let's create the recommended index and see how the situation improves:
Let's run our query again in the Compass explain plan:
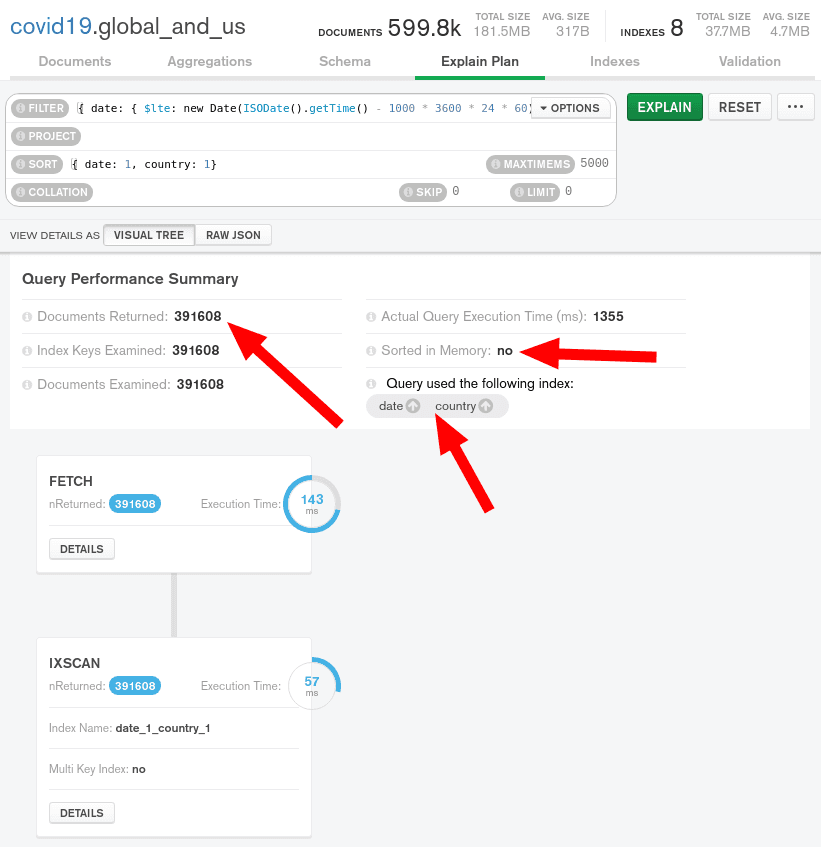
This time, in-memory sort is no longer used, as we can return documents
in the same order they appear in our index. 391608 documents are
returned and we are using the correct index. This query is MUCH more
memory efficient than the previous one.
Now that our index is created, we can finally start the archiving
process.
Just before we start our archiving process, let's run an aggregation
pipeline in MongoDB Compass to check the content of our collection.
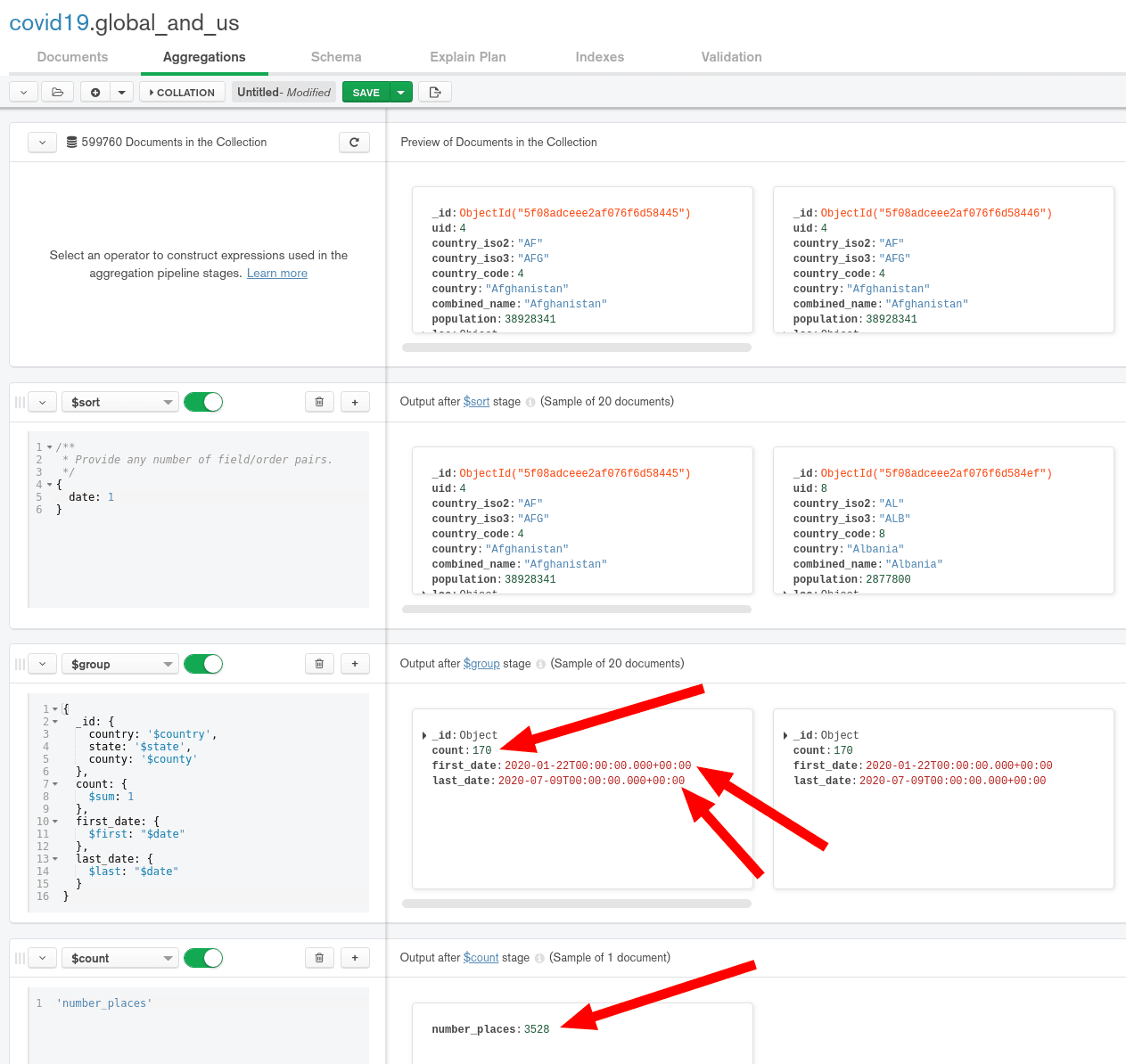
As you can see, by grouping the documents by country, state and county,
we can see:
- how many days are reported:
170, - the first date:
2020-01-22T00:00:00.000+00:00, - the last date:
2020-07-09T00:00:00.000+00:00, - the number of places being monitored:
3528.
Once started, your Online Archive will look like this:
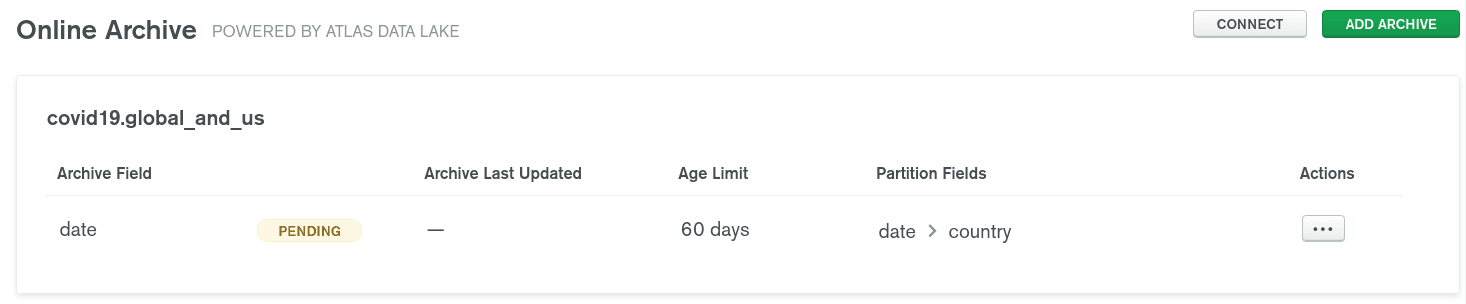
When the initialisation is done, it will look like this:
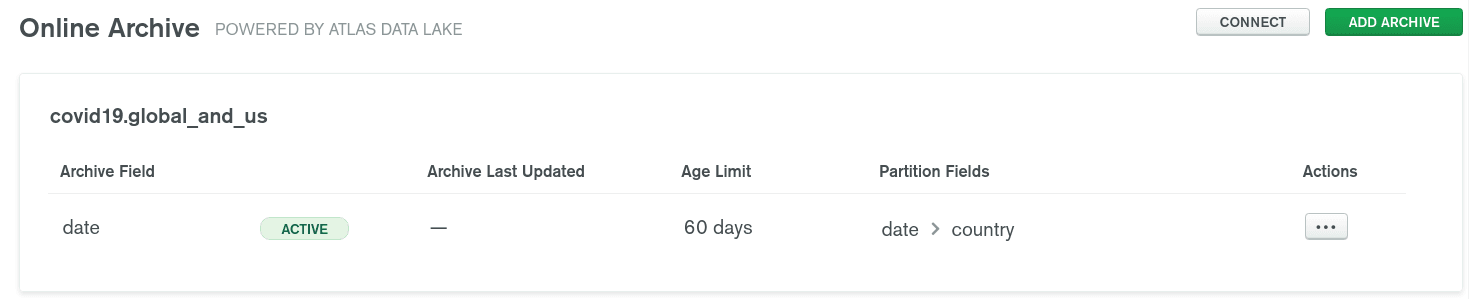
After some times, all your documents will be migrated in the underlying
cloud object storage.
In my case, as I had 599760 in my collection and 111 days have been
moved to my cloud object storage, I have
599760 - 111 * 3528 = 208152
documents left in my collection in MongoDB Atlas.Good. Our data is now archived and we don't need to upgrade our cluster
to a higher cluster tier!

Usually, archiving data rhymes with "bye bye data". The minute you
decide to archive it, it's gone forever and you just take it out of the
old dusty storage system when the actual production system just burnt to
the ground.
Let me show you how you can keep access to the ENTIRE dataset we
just archived on my cloud object storage using MongoDB Atlas Data
Federation.
First, let's click on the CONNECT button. Either directly in the
Online Archive tab:
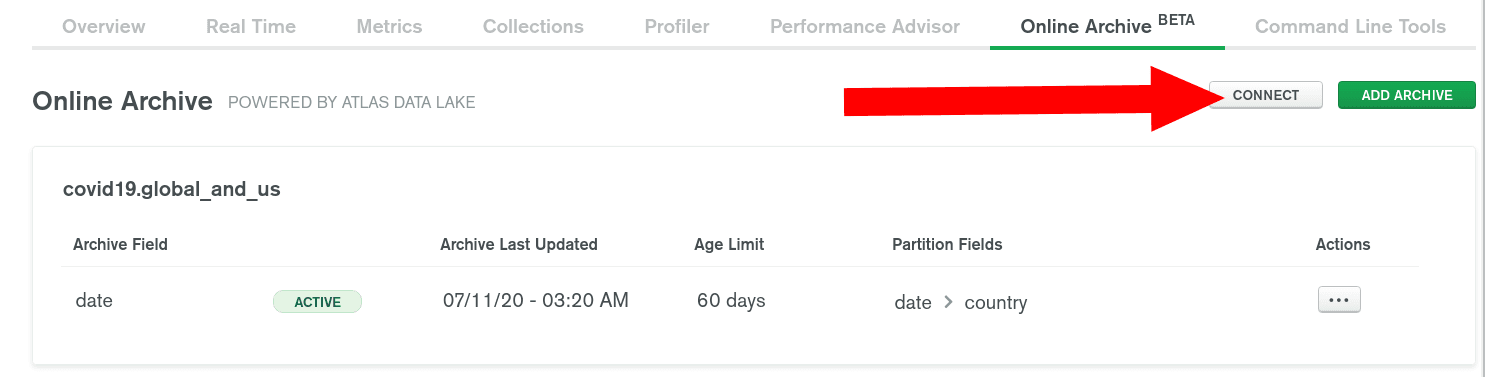
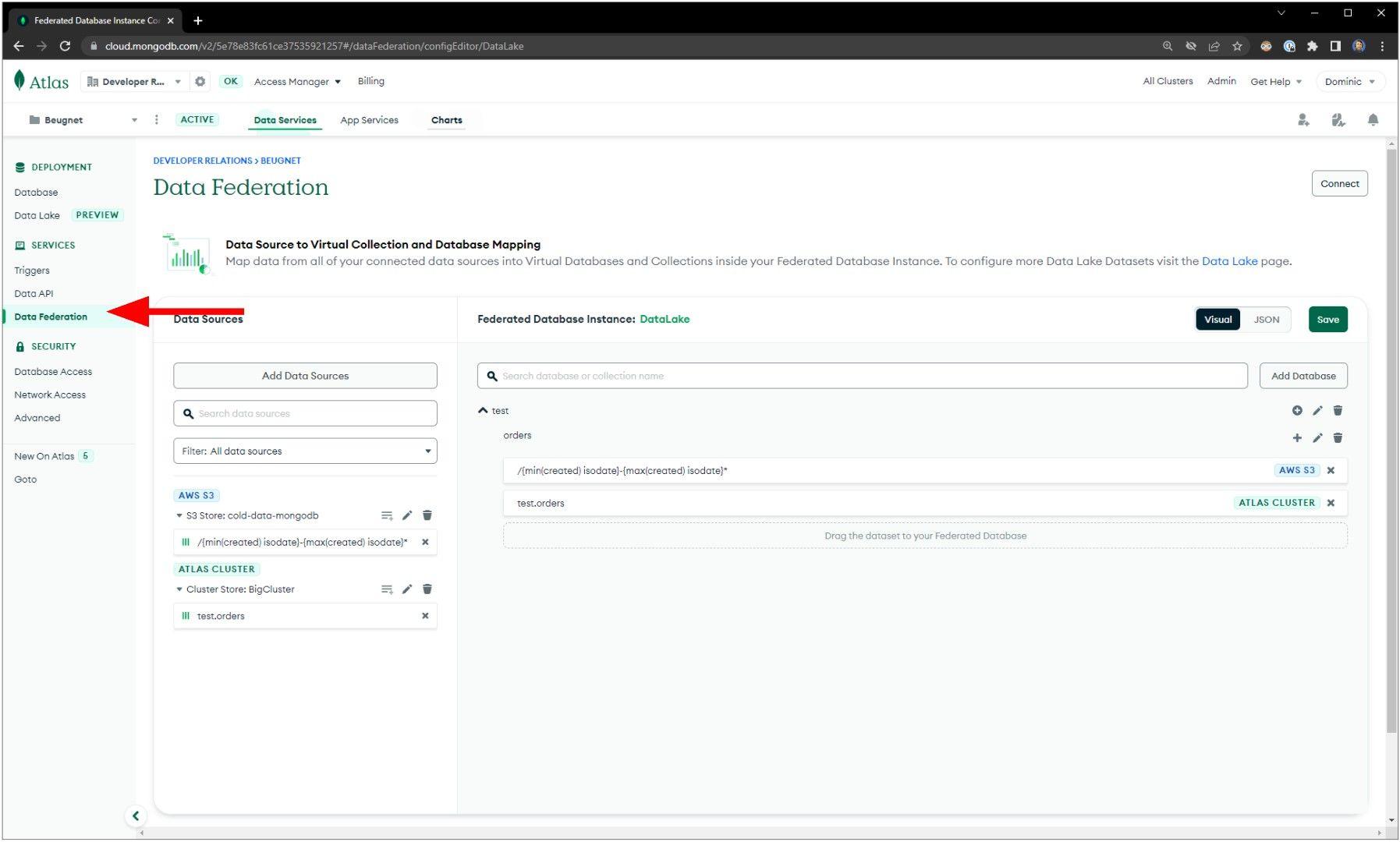
Or head to the Data Federation menu on the left to find your automatically
configured Data Lake environment.
Retrieve the connection command line for the Mongo Shell:
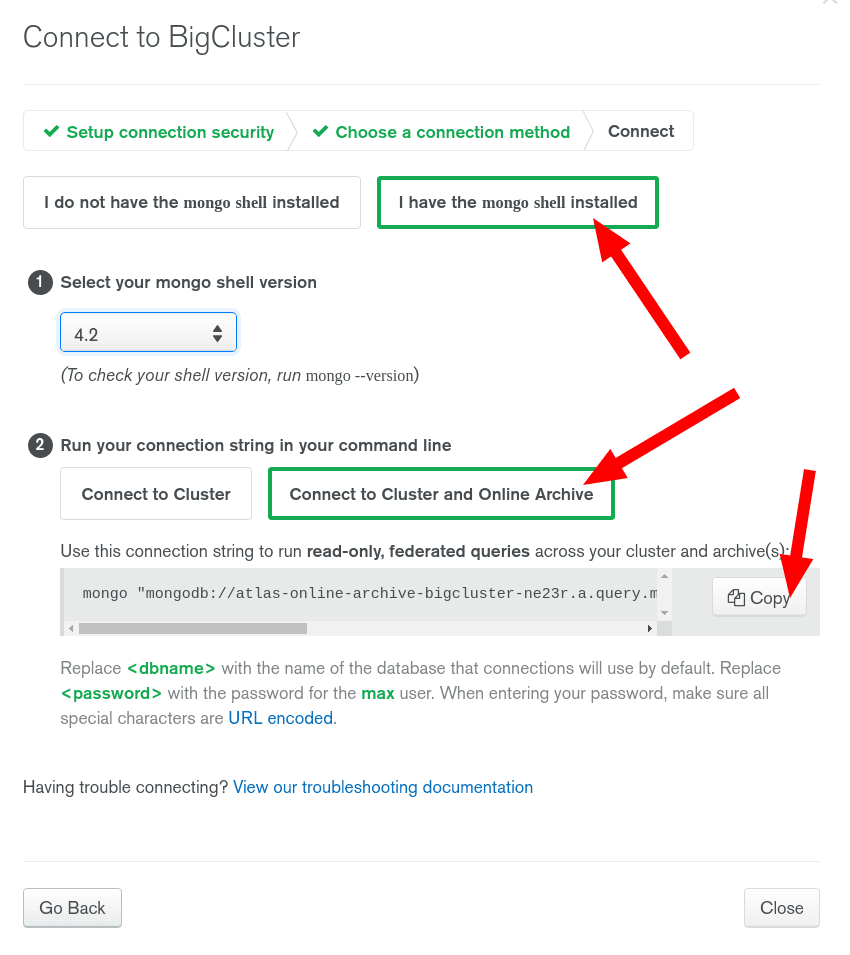
Make sure you replace the database and the password in the command. Once
you are connected, you can run the following aggregation pipeline:
And here is the same query in command line - easier for a quick copy &
paste.
Here is the result I get:
As you can see, even if our cold data is archived, we can still access
our ENTIRE dataset even though it was partially archived. The first
date is still January 22nd and the last date is still July 9th for a
total of 170 days.
MongoDB Atlas Online Archive is your new best friend to retire and store
your cold data safely in cloud object storage with just a few clicks.
In this tutorial, I showed you how to set up an Online Archive to automatically archive your data to fully-managed cloud object storage while retaining easy access to query the entirety of the dataset in-place, across sources, using Atlas Data Federation.
Just in case this blog post didn't make it clear, Online Archive is
NOT a replacement for backups or a backup
strategy. These are 2
completely different topics and they should not be confused.
If you have questions, please head to our developer community
website where the MongoDB engineers and
the MongoDB community will help you build your next big idea with
MongoDB.
To learn more about MongoDB Atlas Data
Federation, read the other blogs
posts in this series below, or check out the
documentation.