Introdução ao LangChain e ao Atlas Vector Search do MongoDB Atlas







Avalie esse Tutorial


Neste tutorial, aproveitaremos o poder do LangChain, MongoDB e OpenAI para ingerir e processar dados criados após o ChatGPT-3.5. Acompanhe o processo para criar seu próprio chatbot capaz de ler documento extensos e fornecer respostas perspicazes a queries complexas!
O LangChain é uma biblioteca Python versátil que permite que os desenvolvedores criem aplicativos baseados em grandes modelos de linguagem (LLMs). Ele ajuda a facilitar a integração de vários LLMs (ChatGPT-3, Hugging Face, etc.) em outras aplicações e a entender e utilizar informações recentes. Como mencionado no nome, LangChain encadeia diferentes componentes, que são chamados de links, para criar um fluxo de trabalho. Cada link individual executa uma tarefa diferente no processo, como acessar uma fonte de dados, chamar um modelo de linguagem, processar a saída, etc. Como a ordem desses links pode ser movida para criar diferentes fluxos de trabalho, o LangChain é superflexível e pode ser usado para criar uma grande variedade de aplicativos.
O MongoDB se integra bem ao LangChain por causa dos recursos de pesquisa semântica fornecidos pelo mecanismo de busca vetorial do MongoDB Atlas. Isso permite a combinação perfeita, os usuários podem consultar com base no significado e não por palavras específicas! Além da integração MongoDB LangChain Python e MongoDB LangChain Javascript, o MongoDB recentemente fez parceria com a LangChain no lançamento dos modelos LangChain para facilitar a criação de aplicativos baseados em IA.
Nossa primeira etapa é garantir que estamos baixando todos os pacotes essenciais de que precisamos para ter sucesso neste tutorial. No Google Colab, execute o seguinte comando:

Aqui, estamos instalando seis pacotes diferentes em um. O primeiro pacote é
langchain (o pacote do framework que estamos usando para integrar os recursos do modelo de linguagem), pypdf (uma biblioteca para trabalhar com documentos PDF no Python), pymongo (o driver oficial do MongoDB para Python para podermos interagir com nosso banco de dados do nosso aplicativo), openai (para que possamos usar os modelos de linguagem do OpenAI), python-dotenv (uma biblioteca usada para ler pares de valores-chave de um arquivo .env) e tiktoken (um pacote para manuseio de token).Depois que este comando for executado e nossos pacotes baixados com sucesso, vamos configurar nosso ambiente. Antes de executar esta etapa, certifique-se de ter salvo sua chave de API e sua string do MongoDB Atlas em um arquivo
.env na raiz do seu projeto. A ajuda para encontrar sua string do MongoDB Atlas pode ser encontrada nos Docs.Fique à vontade para dar o nome que quiser ao seu banco de dados, à sua coleção e até mesmo ao seu índice de pesquisa vetorial. Basta continuar a usar os mesmos nomes durante o tutorial. O sucesso desse bloco de código garante que o banco de dados e a coleção sejam criados em seu MongoDB cluster.
Vamos carregar o PDF
GPT-4 Technical Report. Conforme mencionado acima, esse relatório foi publicado após a data limite de informações do ChatGPT da OpenAI, portanto, o modelo de aprendizado não foi treinado para responder perguntas sobre as informações incluídas neste documento de 100 páginas.O pacote LangChain nos ajudará a responder a quaisquer perguntas que tenhamos sobre este PDF. Vamos carregar nossos dados:
Neste bloco de código, estamos carregando nosso PDF, usando um comando para fazer a divisão dos dados em várias partes e, em seguida, inserindo os documentos em nossa coleção para que possamos usar nosso Atlas Search nos dados inseridos.
Para testar e ter certeza de que nossos dados estão carregados corretamente, execute um teste:
Sua saída deve ser semelhante a esta:
![saída do nosso comando docs[0] para ver se nossos dados estão carregados corretamente](https://www.mongodb.com/developer/_next/image/?url=https%3A%2F%2Fimages.contentstack.io%2Fv3%2Fassets%2Fblt39790b633ee0d5a7%2Fbltffc8c7af0758989d%2F65733c20c6be9382d6e0256f%2Flanchain1.png&w=3840&q=75)
Vamos até a interface de usuário do MongoDB Atlas para criar nosso índice de pesquisa vetorial. Primeiro, clique na aba "Search" e, em seguida, em "Create Search Index.". Você será direcionado para esta página. Clique em "JSON Editor. "
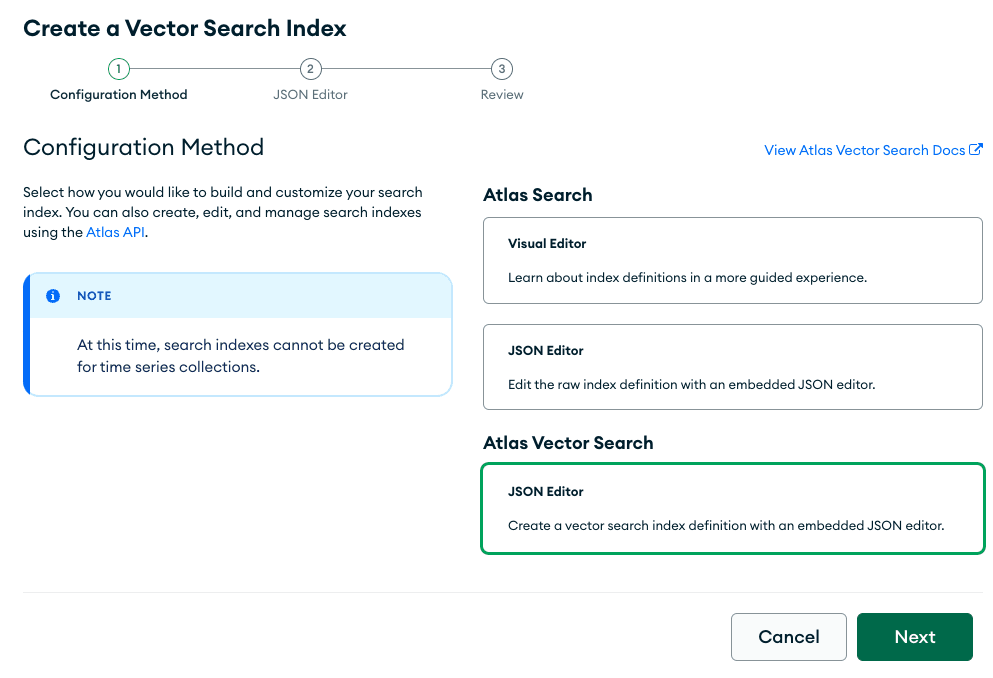
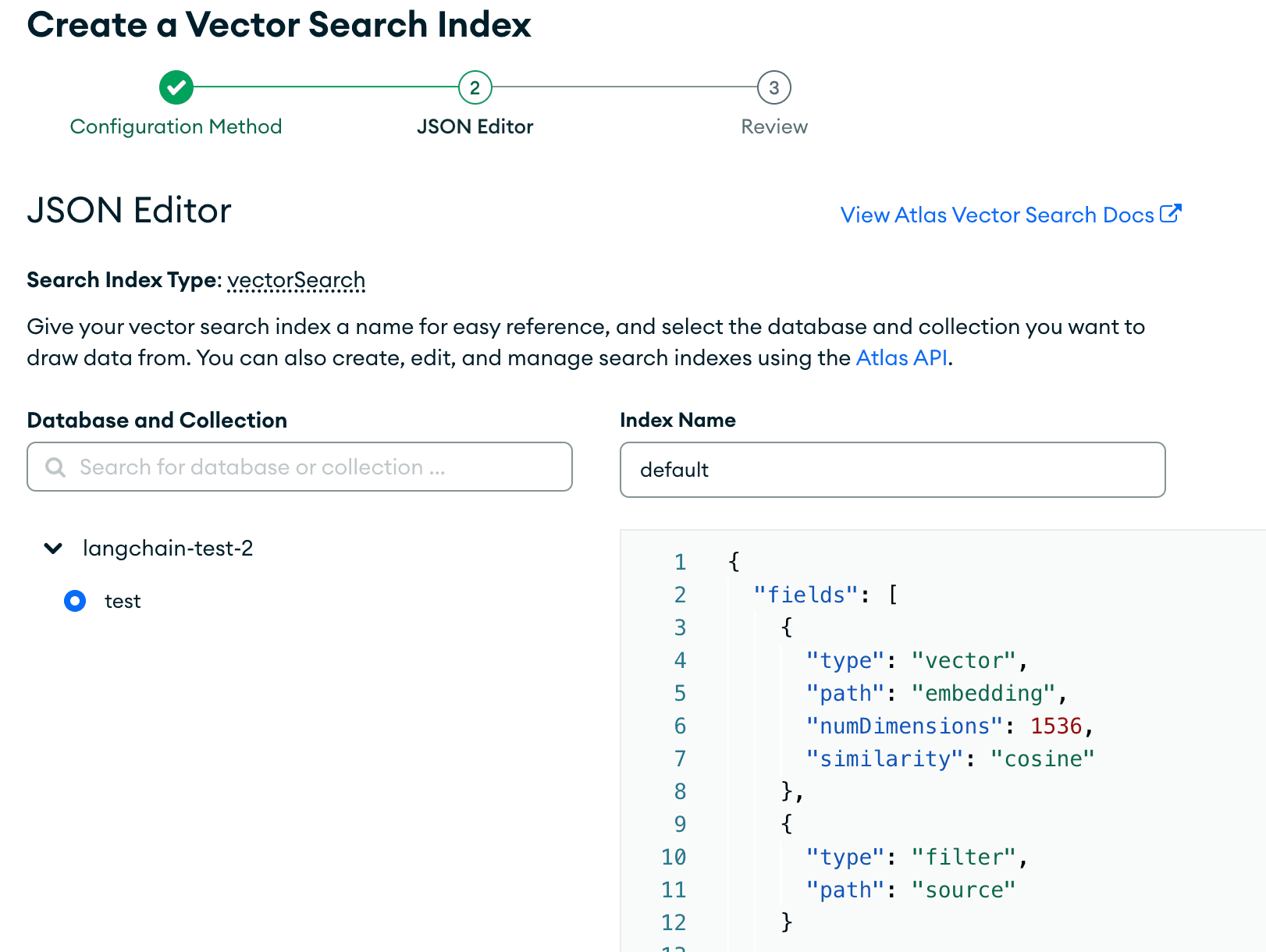
Certifique-se de que o banco de dados e a coleção corretos estejam pressionados e de que você tenha escolhido o nome correto do índice, que foi definido acima. Em seguida, cole o índice de pesquisa que estamos usando para este tutorial:
Esses campos devem especificar o nome do campo em nossos documentos. Com
embedding, estamos especificando que as dimensões do modelo usado para incorporar são 1536, e a função de similaridade usada para encontrar os vizinhos k mais próximos é cosine. É crucial que as dimensões em nosso índice de pesquisa correspondam às do modelo de linguagem que estamos usando para incorporar nossos dados.Confira nossa documentação do Vector Search para obter mais informações sobre as definições de configuração do índice.
Depois de configurado, ficará assim:
Crie o índice de pesquisa e deixe-o carregar.
Agora, estamos prontos para consultar nossos dados! Neste tutorial, mostraremos várias maneiras de executar queries. Vamos utilizar filtros junto com o Vector Search para ver nossos resultados. Vamos começar. Certifique-se de que está conectado ao seu cluster antes de tentar executar a query, caso contrário, ela não funcionará.
Para começar, vamos primeiro ver um exemplo usando o LangChain para realizar uma pesquisa semântica:
Isso dá o resultado:

E nos fornece os resultados relevantes que correspondem semanticamente à intenção por trás da pergunta. Agora, vamos ver o que acontece quando fazemos uma pergunta usando o LangChain.
Execute esse bloco de código para ver o que acontece quando fazemos perguntas para ver nossos resultados:
Após a execução, obtemos o resultado:
Isso fornece uma resposta sucinta à nossa pergunta, com base na fonte de dados fornecida.
Parabéns! Você carregou com sucesso dados externos e os consultou usando o LangChain e o MongoDB. Para obter mais informações sobre o MongoDB Vector Search, visite nossa documentação