IoT and MongoDB: Powering Time Series Analysis of Household Power Consumption






Rate this tutorial


IoT (Internet of Things) systems are increasingly becoming a part of our daily lives, offering smart solutions for homes and businesses.
This article will explore a practical case study on household power consumption, showcasing how MongoDB's time series collections can be leveraged to store, manage, and analyze data generated by IoT devices efficiently.
Time series collections in MongoDB effectively store time series data — a sequence of data points analyzed to observe changes over time.
Time series collections provide the following benefits:
- Reduced complexity for working with time series data
- Improved query efficiency
- Reduced disk usage
- Reduced I/O for read operations
- Increased WiredTiger cache usage
Generally, time series data is composed of the following elements:
- The timestamp of each data point
- Metadata (also known as the source), which is a label or tag that uniquely identifies a series and rarely changes
- Measurements (also known as metrics or values), representing the data points tracked at increments in time — generally key-value pairs that change over time
This case study focuses on analyzing the data set with over two million data points of household electric power consumption, with a one-minute sampling rate over almost four years.
The dataset includes the following information:
- date: Date in format dd/mm/yyyy
- time: Time in format hh:mm
- global_active_power: Household global minute-averaged active power (in kilowatt)
- global_reactive_power: Household global minute-averaged reactive power (in kilowatt)
- voltage: Minute-averaged voltage (in volt)
- global_intensity: Household global minute-averaged current intensity (in ampere)
- sub_metering_1: Energy sub-metering No. 1 (in watt-hour of active energy); corresponds to the kitchen, containing mainly a dishwasher, an oven, and a microwave (hot plates are not electric but gas-powered)
- sub_metering_2: Energy sub-metering No. 2 (in watt-hour of active energy); corresponds to the laundry room, containing a washing machine, a tumble drier, a refrigerator, and a light.
- sub_metering_3: Energy sub-metering No. 3 (in watt-hour of active energy); corresponds to an electric water heater and an air conditioner
To define and model our time series collection, we will use the Mongoose library. Mongoose, an Object Data Modeling (ODM) library for MongoDB, is widely used in the Node.js ecosystem for its ability to provide a straightforward way to model our application data.
The schema will include:
- timestamp: A combination of the “date” and “time” fields from the dataset.
- global_active_power: A numerical representation from the dataset.
- global_reactive_power: A numerical representation from the dataset.
- voltage: A numerical representation from the dataset.
- global_intensity: A numerical representation from the dataset.
- sub_metering_1: A numerical representation from the dataset.
- sub_metering_2: A numerical representation from the dataset.
- sub_metering_3: A numerical representation from the dataset.
To configure the collection as a time series collection, an additional “timeseries” configuration with “timeField” and “granularity” properties is necessary. The “timeField” will use our schema’s “timestamp” property, and “granularity” will be set to “minutes” to match the dataset's sampling rate.
Additionally, an index on the “timestamp” field will be created to enhance query performance — note that you can query a time series collection the same way you query a standard MongoDB collection.
The resulting schema is structured as follows:

For further details on creating time series collections, refer to MongoDB's official time series documentation.
The dataset is provided as a .txt file, which is not directly usable with MongoDB. To import this data into our MongoDB database, we need to preprocess it so that it aligns with our database schema design.
This can be accomplished by performing the following steps:
- Connect to MongoDB.
- Load data from the .txt file.
- Normalize the data and split the content into lines.
- Parse the lines into structured objects.
- Transform the data to match our MongoDB schema model.
- Filter out invalid data.
- Insert the final data into MongoDB in chunks.
Here is the Node.js script that automates these steps:
Before you start the script, you need to make sure that your environment variables are set up correctly. To do this, create a file named “.env” in the root folder, and add a line for “MONGODB_CONNECTION_STRING”, which is your link to the MongoDB database.
The content of the .env file should look like this:
For more details on constructing your connection string, refer to the official MongoDB documentation.
Once the data has been inserted into our MongoDB time series collection, MongoDB Atlas Charts can be used to effortlessly connect to and visualize the data.
In order to connect and use MongoDB Atlas Charts, we should:
- Establish a connection to the time series collection as a data source.
- Associate the desired fields with the appropriate X and Y axes.
- Implement filters as necessary to refine the data displayed.
- Explore the visualizations provided by Atlas Charts to gain insights.
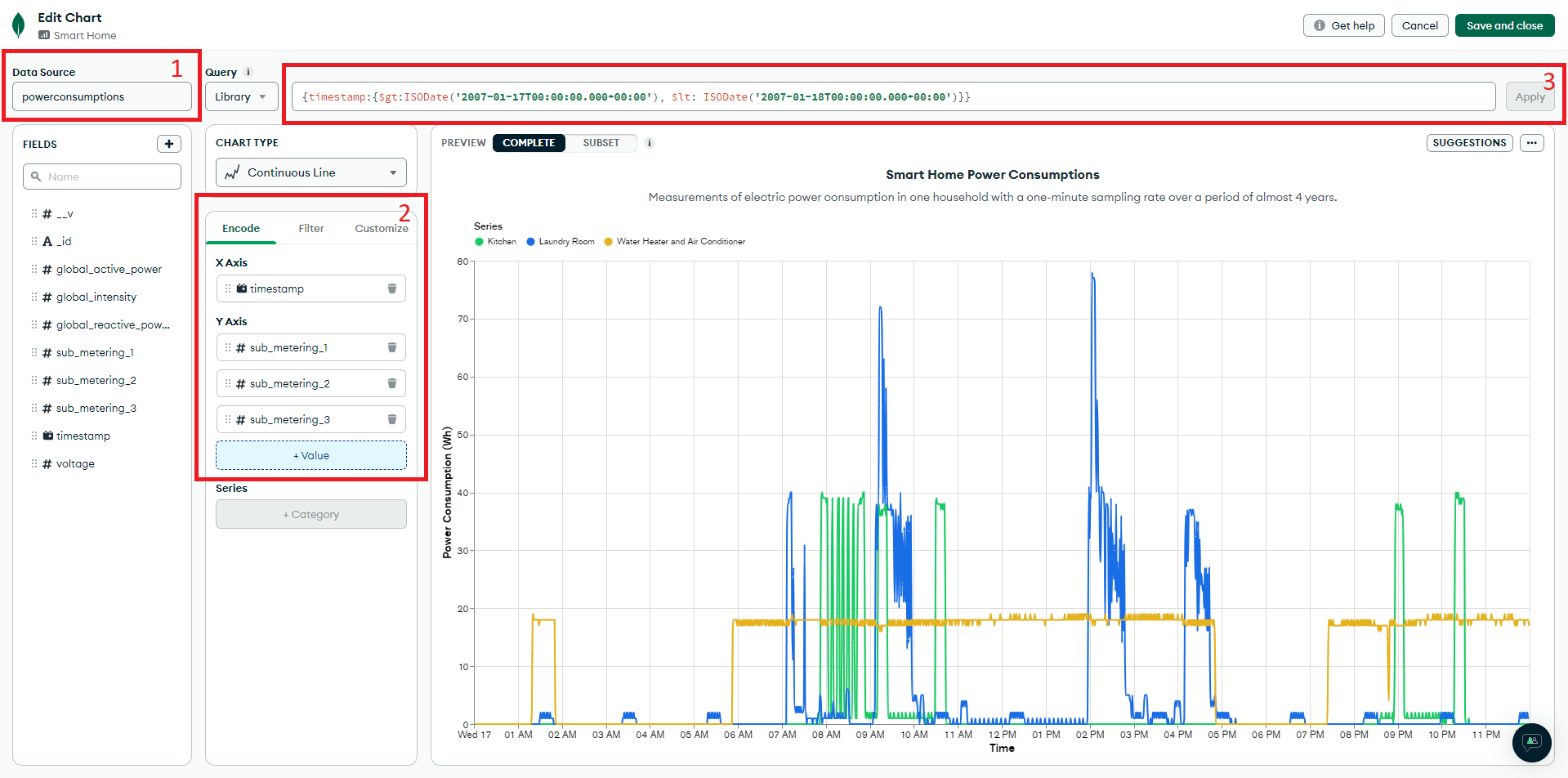
In the above example, we visualized the power consumption from various sources within a single day. The visualization revealed distinct usage patterns: Kitchen equipment was primarily used in the morning and evening, laundry room equipment was active around noon, and the water heater and air conditioner showed continuous use from morning to evening.
For the displayed visualization, we used a query to filter the data for a specific date:
If you want to change what is shown in the charts, you can apply different filters or aggregation pipelines to the data, tailoring the results according to your needs.
This article demonstrates the powerful capabilities of MongoDB when integrated with IoT systems. By leveraging MongoDB's time series collection, we can efficiently store, manage, and analyze the large volumes of time-series data generated by IoT devices.
The case study on household power consumption not only showcases the practical applications of IoT in our daily lives but also highlights how MongoDB can help us get a deeper understanding of IoT data sets.
Through visualization with MongoDB Atlas Charts, we have gained significant insights into power consumption patterns. This not only helps in making informed decisions but also opens the door for significant improvements in energy efficiency and cost savings.
As we have explored the capabilities of MongoDB in handling IoT data and visualizing it with Atlas Charts, I hope it gets you excited to work more on your own data projects. I invite you to join the MongoDB Community Forums to share your experiences, ask questions, and collaborate with fellow enthusiasts. Whether you are seeking advice, sharing your latest project, or exploring innovative uses of MongoDB, the community is a great place to continue the conversation.
Top Comments in Forums
There are no comments on this article yet.