Unlocking Semantic Search: Building a Java-Powered Movie Search Engine with Atlas Vector Search and Spring Boot






Rate this tutorial


In the rapidly evolving world of technology, the quest to deliver more relevant, personalized, and intuitive search results has led to the rise in popularity of semantic search.
MongoDB's Vector Search allows you to search your data related semantically, making it possible to search your data by meaning, not just keyword matching.
In this tutorial, we'll delve into how we can build a Spring Boot application that can perform a semantic search on a collection of movies by their plot descriptions.
Before you get started, there are a few things you'll need.
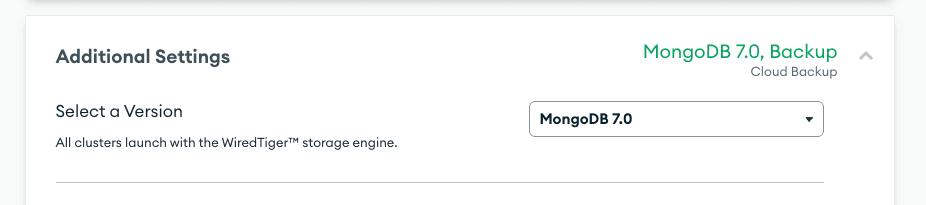
Visit the MongoDB Atlas dashboard and set up your cluster. In order to take advantage of the
$vectorSearch operator in an aggregation pipeline, you need to run MongoDB Atlas 6.0.11 or higher.Selecting your MongoDB Atlas version is available at the bottom of the screen when configuring your cluster under "Additional Settings."
When you’re setting up your deployment, you’ll be prompted to set up a database user and rules for your network connection.
For this project, we're going to use the sample data MongoDB provides. When you first log into the dashboard, you will see an option to load sample data into your database.

If you look in the
sample_mflix database, you'll see a collection called embedded_movies. These documents contain a field called plot_embeddings that holds an array of floating point numbers (our vectors). These numbers are gibberish to us when looked at directly with the human eye but are going to allow us to perform our semantic search for movies based on their plot. If you want to embed your own data, you'll be able to use the methods in this tutorial to do so, or you can check out the tutorial that shows you how to set up a trigger in your database to automatically embed your data.In order to use the
$vectorSearch operator on our data, we need to set up an appropriate search index. Select the "Search" tab on your cluster and click the "Create Search Index."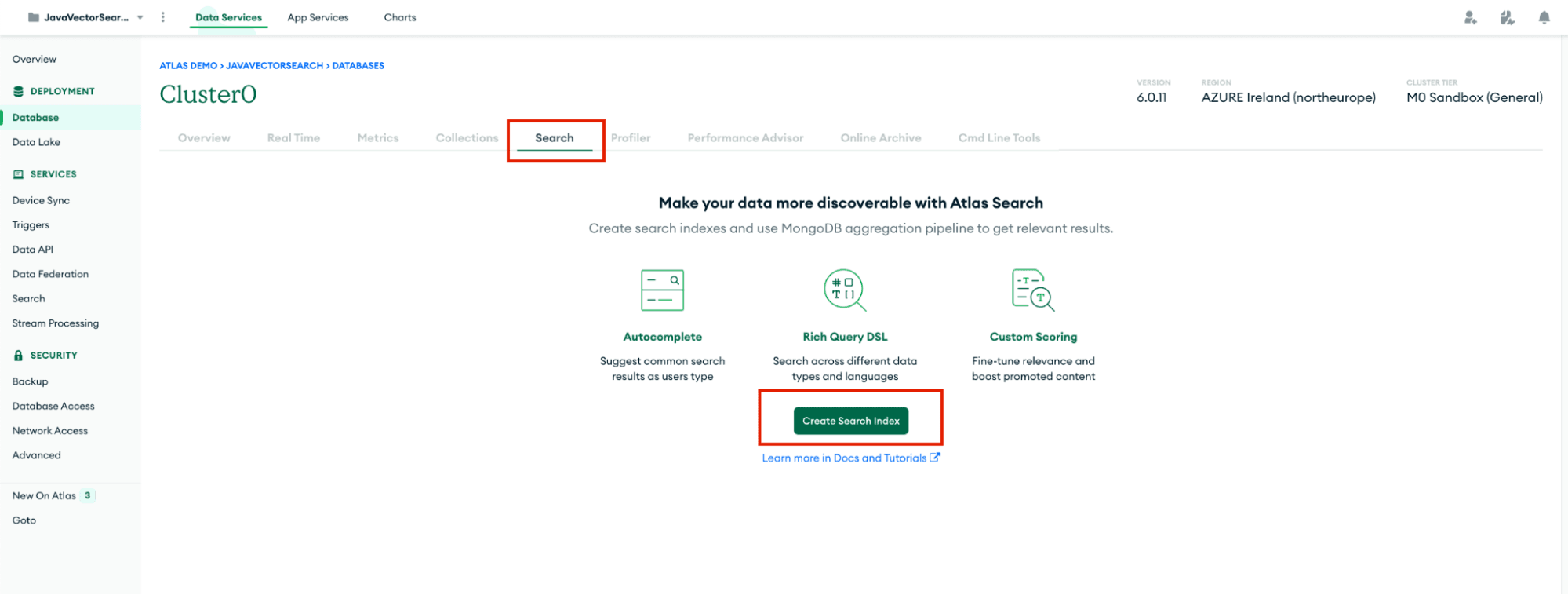
We want to choose the "JSON Editor Option" and click "Next."
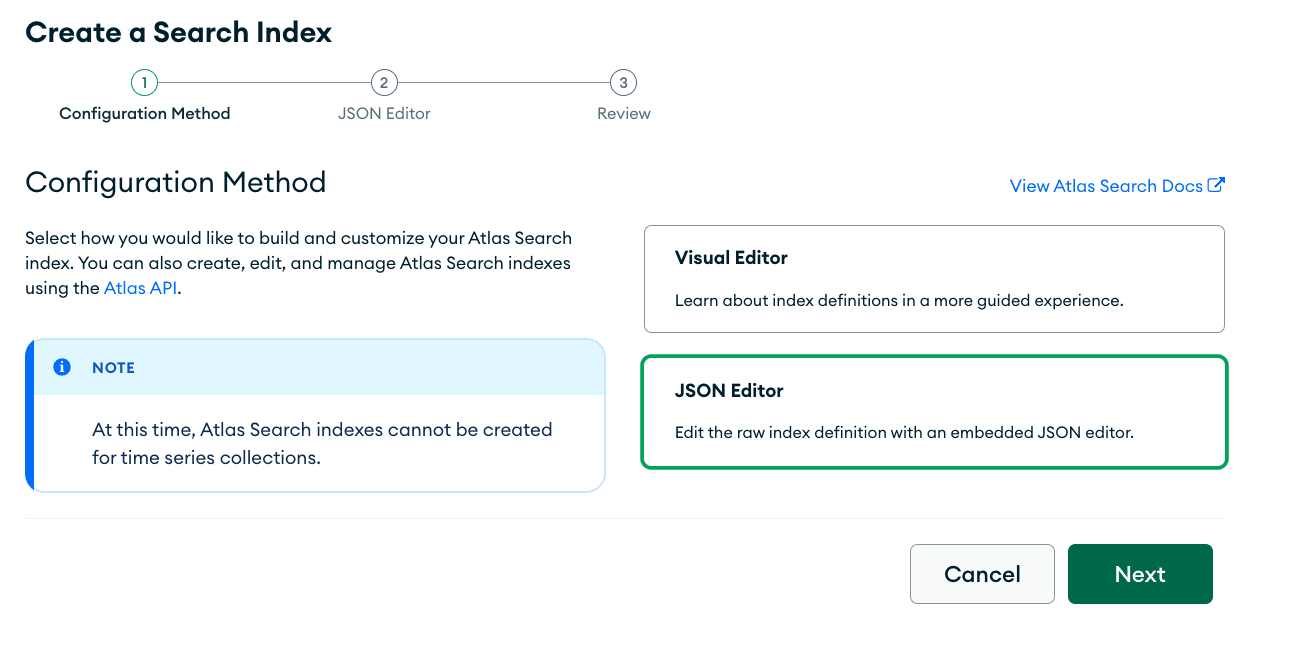
On this page, we're going to select our target database,
sample_mflix, and collection embedded_movies, for this tutorial.The name isn’t too important, but name the index —
PlotVectorSearch, for example — and copy in the following JSON.

The fields specify the embedding field name in our documents,
plot_embedding, the dimensions of the model used to embed, 1536, and the similarity function to use to find K-nearest neighbors, dotProduct. It's very important that the dimensions in the index match that of the model used for embedding. This data has been embedded using the same model as the one we'll be using, but other models are available and may use different dimensions.To set up our project, let's use the Spring Initializr. This will generate our pom.xml file which will contain our dependencies for our project.
For this project, you want to select the options in the screenshot below, and create a JAR:

- Project: Maven
- Language: Java
- Dependencies: Spring Reactive Web and Spring Data Reactive MongoDB
- Generate: JAR
Open the Maven project in the IDE of your choice and let's write some code!
Before we do anything, open your pom.xml file. In the properties section, you will need to add the following:
This will force your Spring Boot API to use the 4.11.0 version of the MongoDB Java drivers. Feel free to use a more up to date version in order to make use of some of the most up to date features, such as the
vectorSearch() method. You will also notice that throughout this application we use the MongoDB Java Reactive Streams. This is because we are creating an asynchronous API. AI operations like generating embeddings can be compute-intensive and time-consuming. An asynchronous API allows these tasks to be processed in the background, freeing up the system to handle other requests or operations simultaneously. Now, let’s get to coding!To represent our document in Java, we will use Plain Old Java Objects (POJOs). The data we're going to handle are the documents from the sample data you just loaded into your cluster. For each document and subdocument, we need a POJO. MongoDB documents bear a lot of resemblance to POJOs already and are straightforward to set up using the MongoDB driver.
In the main document, we have three subdocuments:
Imdb, Tomatoes, and Viewer. Thus, we will need four POJOs for our Movie document.We first need to create a package called
com.example.mdbvectorsearch.model and add our class Movie.java.We use the
@BsonProperty("_id") to assign our _id field in JSON to be mapped to our Id field in Java, so as to not violate Java naming conventions.Add another class called
Imdb.Yet another called
Tomatoes.And finally,
Viewer.Tip: For creating the getters and setters, many IDEs have shortcuts.
In your main file, set up a package
com.example.mdbvectorsearch.config and add a class, MongodbConfig.java. This is where we will connect to our database, and create and configure our client. If you're used to using Spring Data MongoDB, a lot of this is usually obfuscated. We are doing it this way to take advantage of some of the latest features of the MongoDB Java driver to support vectors.From the MongoDB Atlas interface, we'll get our connection string and add this to our
application.properties file. We'll also specify the name of our database here.Now, in your
MongodbConfig class, import these values, and denote this as a configuration class with the annotation @Configuration.Next, we need to create a Client and configure it to handle the translation to and from BSON for our POJOs. Here we configure a
CodecRegistry to handle these conversions, and use a default codec as they are capable of handling the major Java data types. We then wrap these in a MongoClientSettings and create our MongoClient.Our last step will then be to get our database, and we're done with this class.
We are going to send the prompt given from the user to the OpenAI API to be embedded.
An embedding is a series (vector) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
This will transform our natural language prompt, such as
"Toys that come to life when no one is looking", to a large array of floating point numbers that will look something like this [-0.012670076, -0.008900887, ..., 0.0060262447, -0.031987168].In order to do this, we need to create a few files. All of our code to interact with OpenAI will be contained in our
OpenAIService.java class and go to com.example.mdbvectorsearch.service. The @Service at the top of our class dictates to Spring Boot that this belongs to this service layer and contains business logic.We use the Spring WebClient to make the calls to the OpenAI API. We then create the embeddings. To do this, we pass in our text and specify our embedding model (e.g.,
text-embedding-ada-002). You can read more about the OpenAI API parameter options in their docs.To pass in and receive the data from the Open AI API, we need to specify our models for the data being received. We're going to add two models to our
com.example.mdbvectorsearch.model package, EmbeddingData.java and EmbeddingResponse.java.We have our database. We are able to embed our data. We are ready to send and receive our movie documents. How do we actually perform our semantic search?
The data access layer of our API implementation takes place in the repository. Create a package
com.example.mdbvectorsearch.repository and add the interface MovieRepository.java.Now, we implement the logic for our
findMoviesByVector method in the implementation of this interface. Add a class MovieRepositoryImpl.java to the package. This method implements the data logic for our application and takes the embedding of user's inputted text, embedded using the OpenAI API, then uses the $vectorSearch aggregation stage against our embedded_movies collection, using the index we set up earlier.For the business logic of our application, we need to create a service class. Create a class called
MovieService.java in our service package.The
getMoviesSemanticSearch method will take in the user's natural language plot description, embed it using the OpenAI API, perform a vector search on our embedded_movies collection, and return the top five most similar results.This service will take the user's inputted text, embed it using the OpenAI API, then use the
$vectorSearch aggregation stage against our embedded_movies collection, using the index we set up earlier.This returns a
Mono wrapping our list of Movie objects. All that's left now is to actually pass in some data and call our function.We’ve got the logic in our application. Now, let’s make it an API! First, we need to set up our controller. This will allow us to take in the user input for our application. Let's set up an endpoint to take in the users plot description and return our semantic search results. Create a
com.example.mdbvectorsearch.service package and add the class MovieController.java.We define an endpoint
/movies/semantic-search that handles get requests, captures the plotDescription as a query parameter, and delegates the search operation to the MovieService.You can use your favorite tool to test the API endpoints but I'm just going to send a cURL command.
Note: We use
%20 to indicate spaces in our URL.Here we call our API with the query,
"A cop from China and a cop from America save a kidnapped girl". There's no title in there but I think it's a fairly good description of a particular action/comedy movie starring Jackie Chan and Chris Tucker. Here's a slightly abbreviated version of my output. Let's check our results!We found Rush Hour to be our top match. Just what I had in mind! If its premise resonates with you, there are a few other films you might enjoy.
You can test this yourself by changing the
plotDescription we have in the cURL command.This tutorial walked through the comprehensive steps of creating a semantic search application using MongoDB Atlas, OpenAI, and Spring Boot.
Semantic search offers a plethora of applications, ranging from sophisticated product queries on e-commerce sites to tailored movie recommendations. This guide is designed to equip you with the essentials, paving the way for your upcoming project.
Thinking about integrating vector search into your next project? Check out this article — How to Model Your Documents for Vector Search — to learn how to design your documents for vector search.
Top Comments in Forums
There are no comments on this article yet.
Rate this tutorial