Como fazer semantic search no MongoDB utilizando o Atlas Vector Search

Benjamin Flast8 min read • Published Jul 19, 2023 • Updated Jan 12, 2024





Avalie esse Tutorial


Você já tentou buscar por algo, mas não encontrou as palavras certas? Você se lembra de algumas características de um filme, mas não consegue lembrar o nome dele? Já tentou comprar outro moletom igual ao que tinha no passado, mas não sabe como procurá-lo? Você está usando LLMs, mas eles só têm informações anteriores à 2021? Gostaria que eles acompanhassem a evolução dos tempos? Então, a pesquisa vetorial pode ser exatamente o que você está procurando.
A pesquisa vetorial é um recurso que permite fazer uma pesquisa semântica, na qual você pesquisa dados com base no significado. Essa técnica emprega modelos de aprendizado de máquina, geralmente chamados codificadores, para transformar texto, áudio, imagens ou outros tipos de dados em vetores de alta dimensão. Esses vetores capturam o significado semântico dos dados, que podem então ser pesquisados para encontrar conteúdo semelhante com base em vetores "near" uns dos outros em um espaço de alta dimensão. Isso pode ser um grande complemento às técnicas tradicionais de pesquisa baseadas em palavras-chave, mas também está havendo um enorme entusiasmo por causa de sua relevância para aumentar os recursos de grandes modelos de linguagem (LLMs), fornecendo verdade fundamental fora do que os LLMs "know.". Em casos de uso de pesquisa, isso permite encontrar resultados relevantes mesmo quando o texto exato não é conhecido. Essa técnica pode ser útil em diversos contextos, como processamento de linguagem natural e sistemas de recomendação.
Observação: como você provavelmente já sabe, o MongoDB Atlas tem suportado pesquisa de texto completo desde 2020, permitindo a pesquisa de rich text em seus dados do MongoDB. A principal diferença entre a pesquisa vetorial e a pesquisa de texto é que a pesquisa vetorial consulta o significado em vez do texto explícito e, portanto, também pode pesquisar dados além do texto.
- Compreensão semântica: em vez de procurar correspondências exatas, a pesquisa vetorial permite a pesquisa semântica. Isso significa que, mesmo que as palavras da query não estejam presentes no índice, mas os significados das frases sejam semelhantes, elas ainda serão consideradas uma correspondência.
- Escalável: a pesquisa vetorial pode ser feita em grandes conjuntos de dados, tornando-a perfeita para casos de uso em que você tem muitos dados.
- Flexível: diferentes tipos de dados, incluindo texto, mas também dados não estruturados, como áudio e imagens, podem ser pesquisados semanticamente.
- Eficiência: ao armazenar os vetores juntamente com os dados originais, você evita a necessidade de sincronizar dados entre seu Application Database e seu armazenamento vetorial tanto no momento da query quanto da gravação.
- Consistência: o armazenamento dos vetores com os dados garante que os vetores estejam sempre associados aos dados corretos. Isso pode ser importante em situações nas quais o processo de geração vetorial pode mudar com o tempo. Ao armazenar os vetores, você pode ter certeza de que sempre tem o vetor correto para um determinado dado.
- Simplicidade: armazenar vetores com os dados simplifica a arquitetura geral de sua aplicação. Não é preciso manter um serviço ou banco de dados separado para os vetores, reduzindo a complexidade e os possíveis pontos de falha em seu sistema.
- Escalabilidade: com o poder do MongoDB Atlas, a pesquisa vetorial no MongoDB é dimensionada horizontal e verticalmente, permitindo que você turbine as cargas de trabalho mais exigentes.
Quer experimentar o Vector Search com o MongoDB de forma rápida e fácil? Confira esta demonstração automatizada no GitHub enquanto percorre pelo tutorial.
Agora, vamos começar a configurar um cluster MongoDB Atlas, que usaremos para armazenar nossas integrações.
Etapa 1: criar uma conta
Para criar um cluster do MongoDB Atlas, primeiro é preciso criar uma conta do MongoDB Atlas se você ainda não tiver uma. Acesse o site do MongoDB Atlas e clique em "Register.".
Etapa 2: criar um novo cluster
Após a criação da conta, você será direcionado para o dashboard do MongoDB Atlas. Você pode criar um cluster no dashboard ou usar nosso provedor público de API, CLI ou Terraform. Para fazer isso no dashboard, clique em "Create Cluster," e, em seguida, escolha a opção de clusters compartilhados. Sugerimos criar um cluster de nível M0.
Se precisar de ajuda, confira nosso tutorial que demonstra a implantação do Atlas usando várias estratégias.
Etapa 3: Crie suas coleções
Agora, vamos criar suas coleções no cluster para que possamos inserir nossos dados. Elas precisam ser criadas agora para que você possa criar um Atlas Trigger que as visará.
Neste tutorial, você pode criar sua própria coleção se tiver dados para usar. Se você quiser usar nossos dados de amostra, precisará primeiro criar uma coleção vazia no cluster para que possamos configurar o trigger para incorporá-los à medida que são inseridos. Vá em frente e crie um banco de dados "sample_mflix" e uma coleção "movies" agora usando a IU, se quiser usar nossos dados de amostra.
Criaremos um Atlas trigger para chamar a API OpenAI sempre que um novo documento for inserido no cluster.
Para prosseguir para a próxima etapa usando o OpenAI, você precisa ter configurado uma conta no OpenAI e criado uma chave de API.
Se não quiser incorporar todos os dados na coleção, você pode usar a coleção "sample_mflix.embedded_movies" para isso, que já tem incorporações geradas pelo Open AI, e simplesmente crie um índice e execute queries do Vector Search.
Etapa 1: Criar um trigger
Para criar um trigger, navegue até a seção "Triggers" no dashboard do MongoDB Atlas e clique em "Add Trigger."
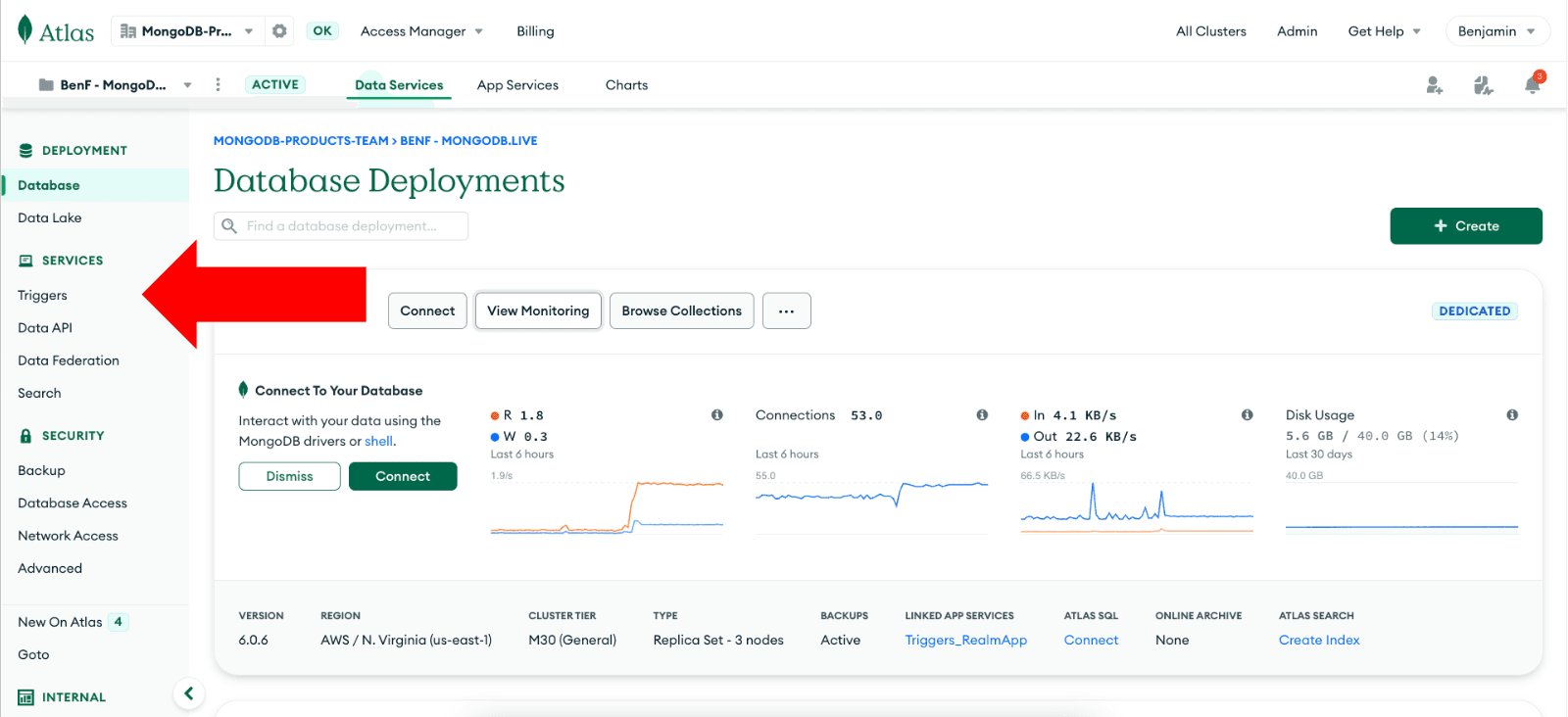
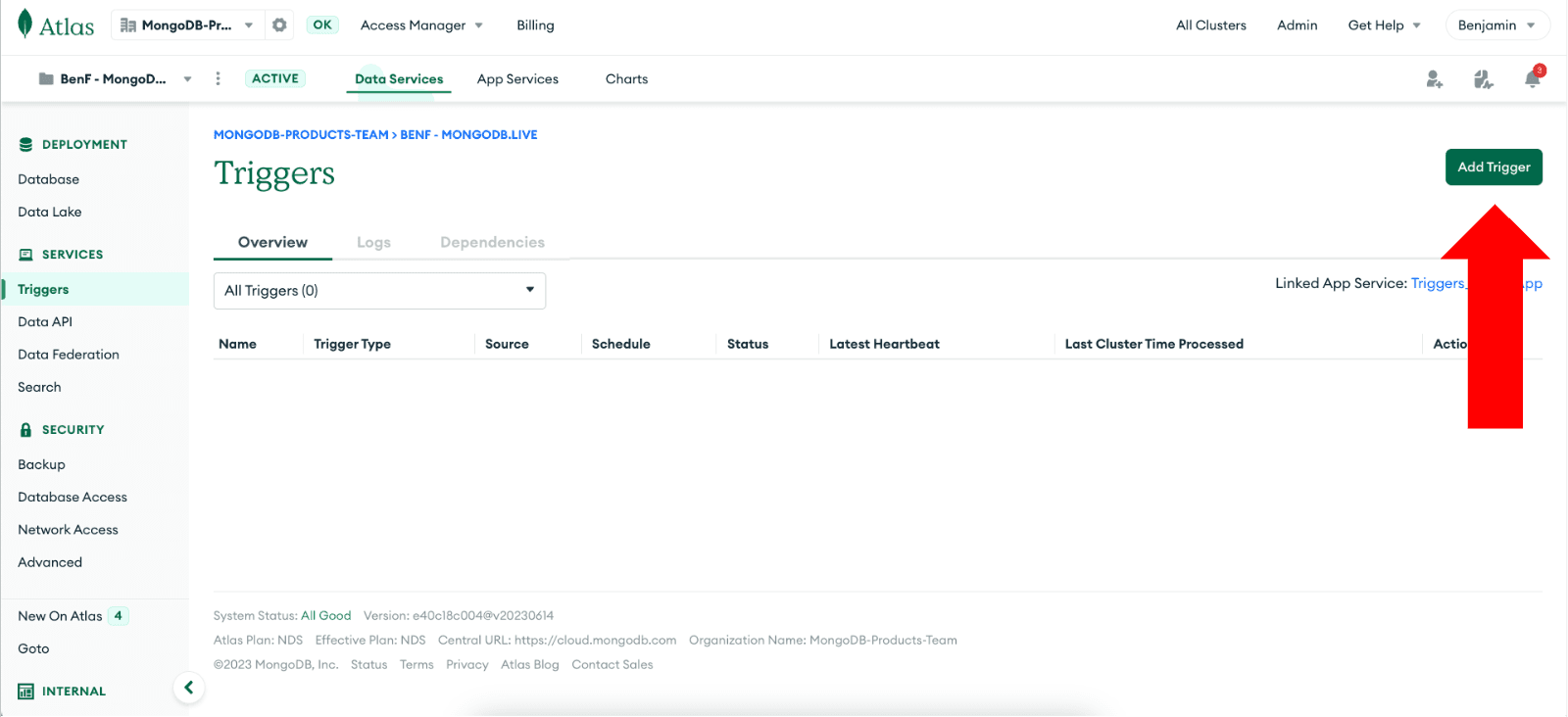
Etapa 2: Configurar segredos e valores para suas credenciais do OpenAI
Vá até "App Services" e selecione seu aplicativo "Triggers".
Clique em “Values.”
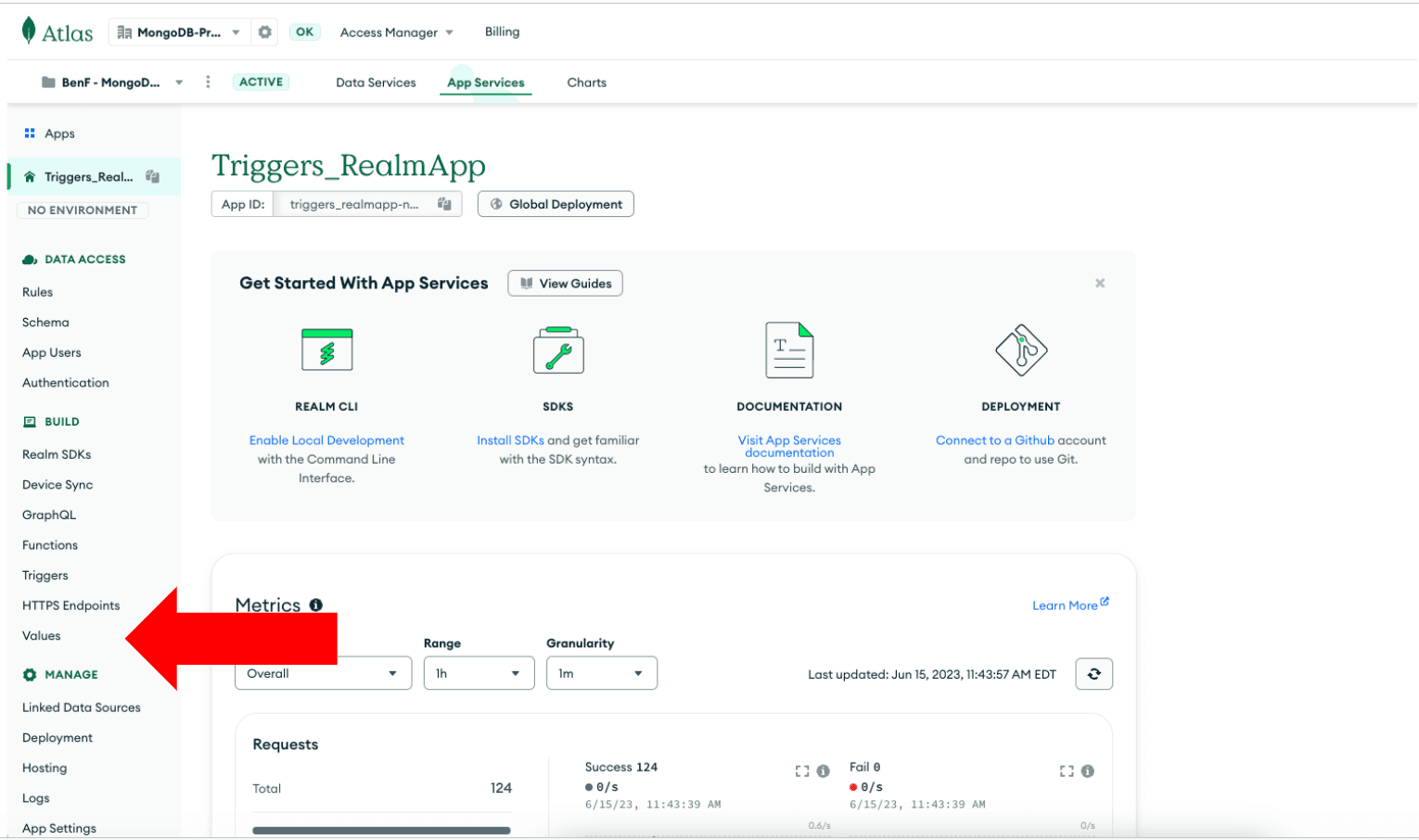
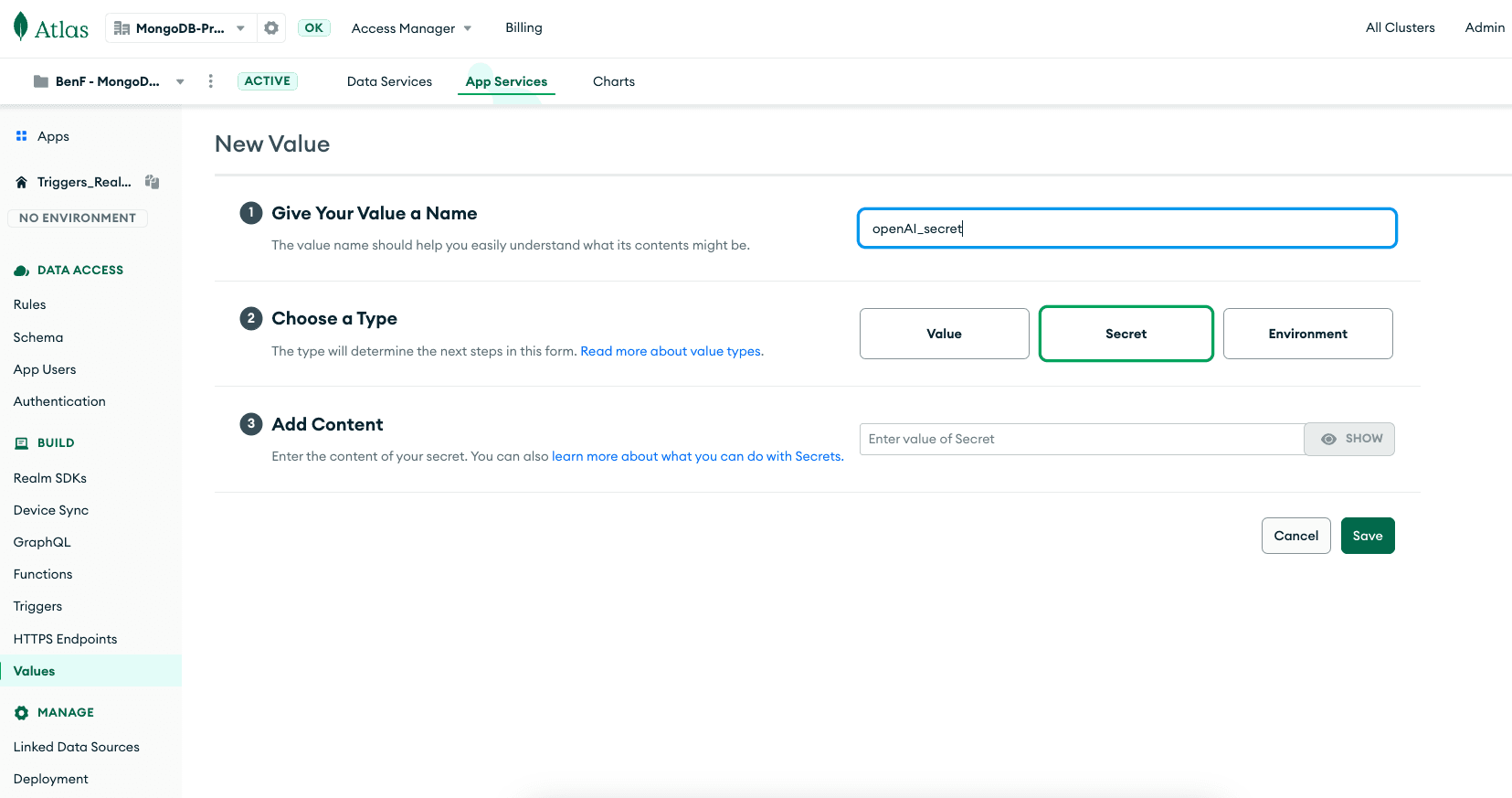
Crie um novo valor

Selecione “Secret” e cole sua chave de API do OpenAI.
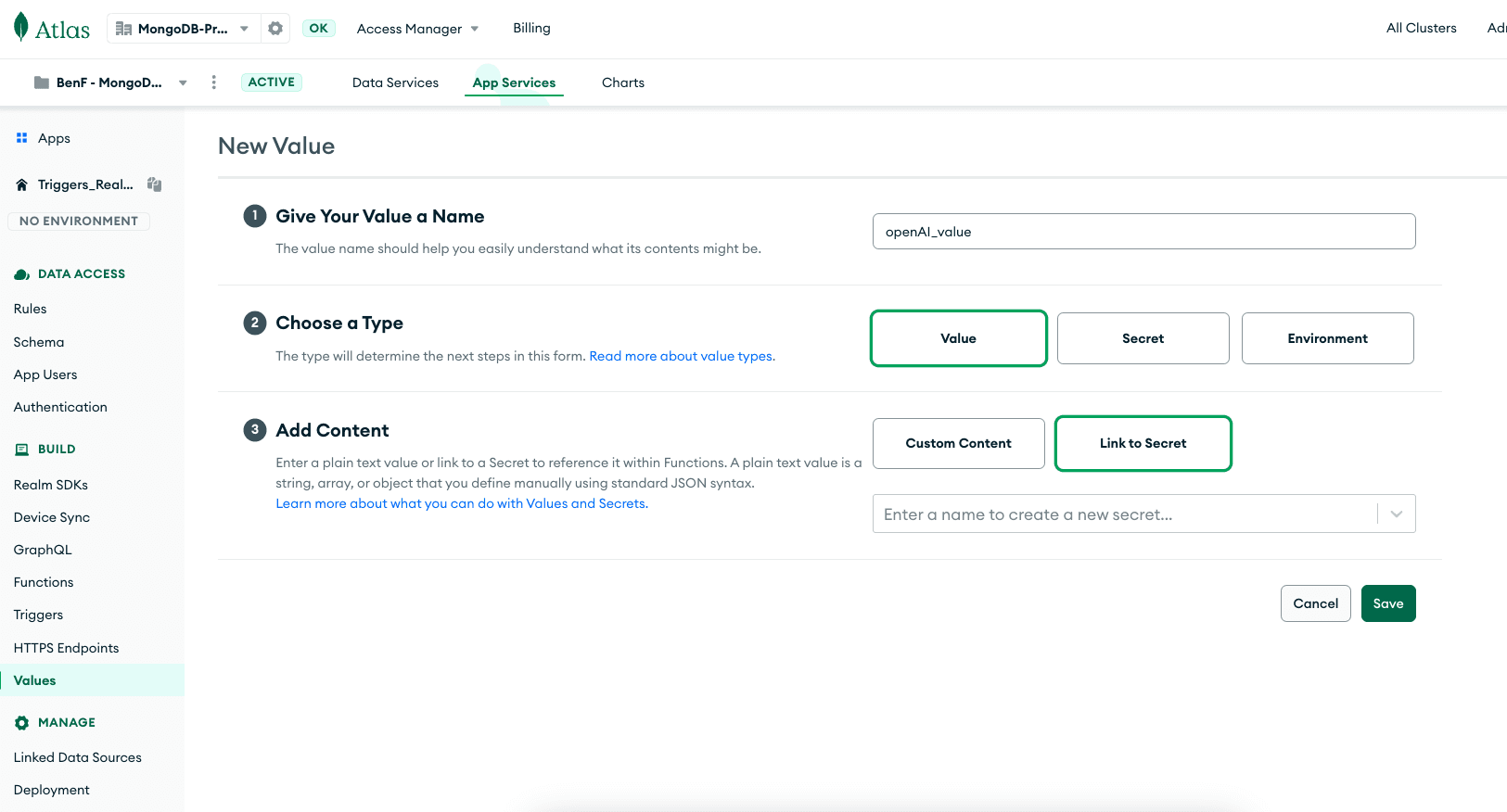
Em seguida, crie outro valor — desta vez, um “Value” — e vincule-o ao seu segredo. É assim que você fará referência segura a essa chave de API em seu trigger.
Agora, você pode voltar para a aba "Data Services" e entrar no menu triggers. Se o trigger criado anteriormente não aparecer, basta adicionar um novo. Ele poderá utilizar os valores que você configurou em App Services anteriormente.
Etapa 3: Configurar o trigger
Selecione o tipo "Database" para o seu trigger. Em seguida, vincule o cluster de origem e defina o "Trigger Source Details" como o Banco de dados e a Coleção para observar as alterações. Neste tutorial, estamos usando o banco de dados "sample_mflix" e a coleção "movies". Defina o tipo de operação como operação "Inserir" "Atualizar" "Substituir". Marque o sinalizador "Full Document" e, em Tipo de evento, escolha "Function."
No Editor de Funções, use o trecho de código abaixo, substituindo Nome do banco de dados e Nome da coleção pelos nomes do banco de dados e da coleção que você deseja usar, respectivamente.
Esse gatilho verá quando um novo documento for criado ou atualizado na coleção. Quando isso acontecer, ele fará uma chamada à API do OpenAI para criar uma incorporação do campo desejado e, em seguida, inserirá essa incorporação vetorial no documento com um novo nome de campo.

Agora, vá até o Atlas Search e crie um índice. Utilize a definição de índice JSON e insira o seguinte, substituindo o nome do campo de incorporação pelo campo de sua escolha. Se você estiver usando o banco de dados sample_mflix, ele deverá ser “plot_embedding” e dar um nome a ele. Usei “moviesPlotIndex” na minha configuração com os dados de amostra.
Primeiro, clique na aba "atlas search" no seu cluster
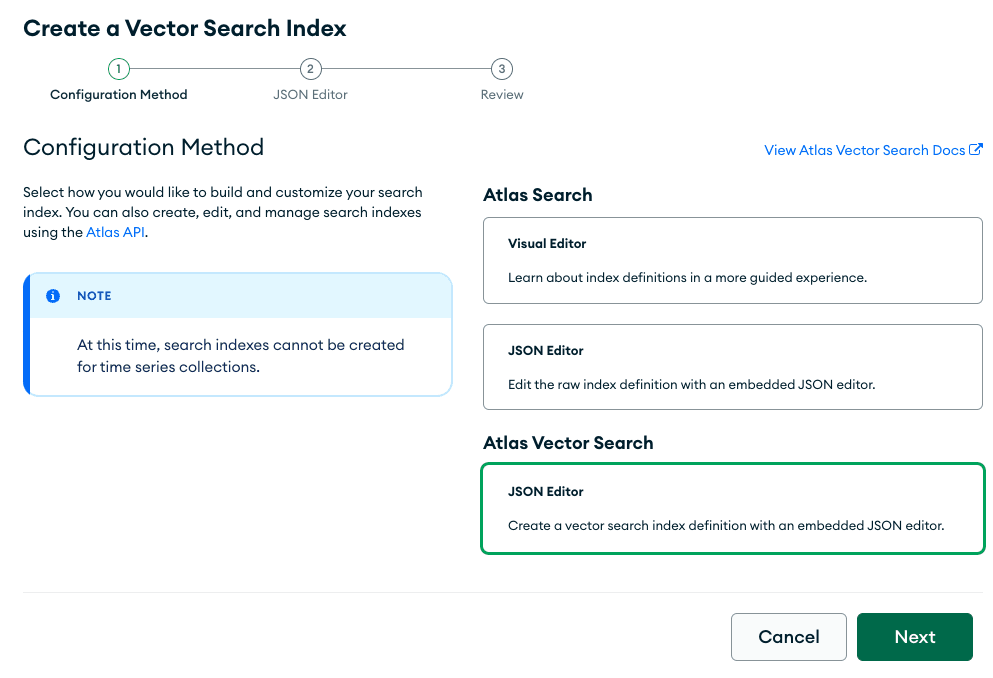
Em seguida, clique em "Create Search Index. "

Crie “JSON Editor.”
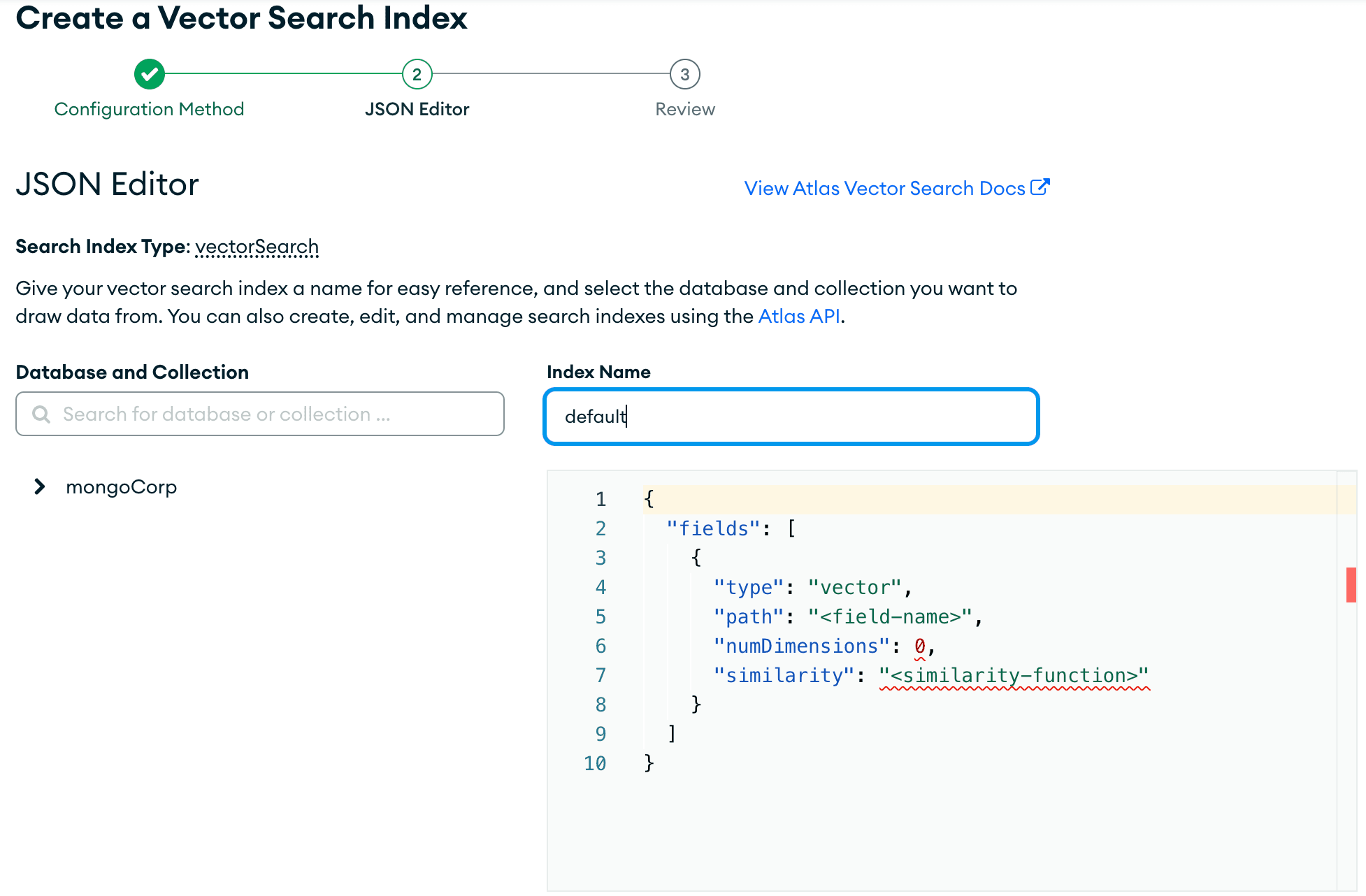
Em seguida, selecione seu banco de dados e coleção à esquerda e um descarte no trecho de código abaixo para sua definição de índice.
Agora, você precisa inserir seus dados. À medida que seus dados forem inseridos, eles serão incorporados usando o script e, em seguida, indexados usando o índice KNN que acabamos de definir.
Se você for usar os dados do filme de amostra, basta acessar o cluster, clicar no menu ... e carregar os dados de amostra. Se tudo tiver sido configurado corretamente, o banco de dados sample_mflix e as coleções de filmes terão as integrações de gráficos criadas no campo "plot" e adicionadas a um novo campo "plot_embeddings".
Depois que os documentos na sua coleção tiverem suas integrações geradas, você poderá realizar uma query. Mas como se trata do uso de pesquisa vetorial, sua query precisa ser transformada em uma integração. Este é um script de exemplo de como você pode adicionar uma função para obter uma incorporação da query e uma função para usar essa incorporação dentro de sua aplicação.
Esse script primeiro transforma sua query em uma incorporação usando a API do OpenAI e, em seguida, consulta seu cluster do MongoDB em busca de documentos com incorporações semelhantes.
O suporte para a fase de pipeline de agregação '$VectorSearch' está disponível com o MongoDB Atlas 6.0.11 e 7.0.2.
Lembre-se de substituir "your_openai_key", "your_mongodb_url", "your_query", "<DB_NAME>" e "<COLLECTION_NAME>" por sua chave OpenAI, URL do MongoDB, query, nome do banco de dados e nome da coleção reais, respectivamente.
E é isso! Você configurou com sucesso um cluster MongoDB Atlas e um Atlas Trigger que chama a API do OpenAI para incorporar documentos quando eles forem inseridos no cluster e você tiver realizado uma query de pesquisa vetorial.
Se você prefere aprender assistindo, confira a versão em vídeo deste artigo!
Avalie esse Tutorial
Relacionado
Tutorial
Crie uma API CRUD com MongoDB, Typescript, Express, Prisma e Zod
Jun. 12, 2024 | 10 minutos de leitura
Tutorial
Adicionando o preenchimento automático aos seus aplicativos NextJS com o Atlas Search
Fev. 28, 2023 | 11 minutos de leitura