How to Use Custom Archival Rules and Partitioning on MongoDB Atlas Online Archive





Rate this tutorial


As of June 2022, the functionality previously known as Atlas Data Lake is now named Atlas Data Federation. Atlas Data Federation’s functionality is unchanged and you can learn more about it here. Atlas Data Lake will remain in the Atlas Platform, with newly introduced functionality that you can learn about here.
Okay, so you've set up a simple MongoDB Atlas Online Archive, and now you might be wondering, "What's next?" In this post, we will cover some more advanced Online Archive use cases, including setting up custom archival rules and how to improve query performance through partitioning.
- The Online Archive feature is available on M10 and greater Atlas clusters that run MongoDB 3.6 or later. So for this demo, you will need to create a M10 cluster in MongoDB Atlas. Click here for information on setting up a new MongoDB Atlas cluster or check out How to Manage Data at Scale With MongoDB Atlas Online Archive.
- Ensure that each database has been seeded by loading sample data into our Atlas cluster. I will be using the
sample_analytics.customersdataset for this demo.
Creating an Online Archive rule based on the date makes sense for a lot of archiving situations, such as automatically archiving documents that are over X years old, or that were last updated Y months ago. But what if you want to have more control over what gets archived? Some examples of data that might be eligible to be archived are:
- Data that has been flagged for archival by an administrator.
- Discontinued products on your eCommerce site.
- User data from users that have closed their accounts on your platform (unless they are European citizens).
- Employee data from employees that no longer work at your company.
There are lots of reasons why you might want to set up custom rules for archiving your cold data. Let's dig into how you can achieve this using custom archive rules with MongoDB Atlas Online Archive. For this demo, we will be setting up an automatic archive of all users in the
sample_analytics.customers collection that have the 'active' field set to false.In order to configure our Online Archive, first navigate to the Cluster page for your project, click on the name of the cluster you want to configure Online Archive for, and click on the Online Archive tab.
Next, click the Configure Online Archive button the first time and the Add Archive button subsequently to start configuring Online Archive for your collection. Then, you will need to create an Archiving Rule by specifying the collection namespace, which will be
sample_analytics.customers.You will also need to specify your custom criteria for archiving documents. You can specify the documents you would like to filter for archival with a MongoDB query, in JSON, the same way as you would write filters in MongoDB Atlas.
Note: You can use any valid MongoDB Query Language (MQL) query, however, you cannot use the empty document argument ({}) to return all documents.
To retrieve the documents staged for archival, we will use the following find command. This will retrieve all documents that have the `active` field set to `false` or do not have an `active` key at all.

Continue setting up your archive, and then you should be done!
Note: It's always a good idea to run your custom queries in the mongo shell first to ensure that you are archiving the correct documents.
Note: Once you initiate an archive and a MongoDB document is queued for archiving, you can no longer edit the document.
One of the reasons we archive data is to access and query it in the future, if for some reason we still need to use it. In fact, you might be accessing this data quite frequently! That's why it's useful to be able to partition your archived data and speed up query times. With Atlas Online Archive, you can specify the two most frequently queried fields in your collection to create partitions in your online archive.
Fields with a moderate to high cardinality (or the number of elements in a set or grouping) are good choices to be used as a partition. Queries that don't contain these fields will require a full collection scan of all archived documents, which will take longer and increase your costs. However, it's a bit of a bit of a balancing act.
For example, fields with low cardinality wont partition the data well and therefore wont improve performance greatly. However, this may be OK for range queries or collection scans, but will result in fast archival performance.
Fields with mid to high cardinality will partition the data better leading to better general query performance, but maybe slightly slower archival performance.
Fields with extremely high cardinality like
_id will lead to poor query performance for everything but "point queries" that query on _id, and will lead to terrible archival performance due to writing many partitions.Note: Online Archive is powered by MongoDB Atlas Data Lake. To learn more about how partitions improve your query performance in Data Lake, see Data Structure in cloud object storage - Amazon S3 or Microsoft Azure Blob Storage.
The specified fields are used to partition your archived data for optimal query performance. Partitions are similar to folders. You can move whichever field to the first position of the partition if you frequently query by that field.
The order of fields listed in the path is important in the same way as it is in Compound Indexes. Data in the specified path is partitioned first by the value of the first field, and then by the value of the next field, and so on. Atlas supports queries on the specified fields using the partitions.
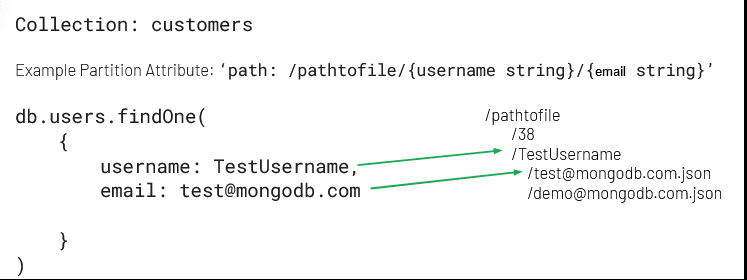
You can specify the two most frequently queried fields in your collection and order them from the most frequently queried in the first position to the least queried field in the second position. For example, suppose you are configuring the online archive for your
customers collection in the sample_analytics database. If your archived field is set to the custom archival rule in our example above, your first queried field is username, and your second queried field is email, your partition will look like the following:Atlas creates partitions first for the
username field, followed by the email. Atlas uses the partitions for queries on the following fields:- the
usernamefield - the
usernamefield and theemailfield
Note: The value of a partition field can be up to a maximum of 700 characters. Documents with values exceeding 700 characters are not archived.
For more information on how to partition data in your Online Archive, please refer to the documentation.
In this post, we covered some advanced use cases for Online Archive to help you take advantage of this MongoDB Atlas feature. We initialized a demo project to show you how to set up custom archival rules with Atlas Online Archive, as well as improve query performance through partitioning your archived data.
If you have questions, please head to our developer community website where the MongoDB engineers and the MongoDB community will help you build your next big idea with MongoDB.