RAG with Atlas Vector Search, LangChain, and OpenAI





With all the recent developments (and frenzy!) around generative AI, there has been a lot of focus on LLMs, in particular. However, there is also another emerging trend that many are unaware of: the rise of vector stores. Vector stores or vector databases play a crucial role in building LLM applications. This puts Atlas Vector Search in the vector store arena that has a handful of contenders.
The goal of this tutorial is to provide an overview of the key-concepts of Atlas Vector Search as a vector store, and LLMs and their limitations. We’ll also look into an upcoming paradigm that is gaining rapid adoption called "retrieval-augmented generation" (RAG). We will also briefly discuss the LangChain framework, OpenAI models, and Gradio. Finally, we will tie everything together by actually using these concepts + architecture + components in a real-world application. By the end of this tutorial, readers will leave with a high-level understanding of the aforementioned concepts, and a renewed appreciation for Atlas Vector Search!
Large language models (LLMs) are a class of deep neural network models that have been trained on vast amounts of text data, which enables them to understand and generate human-like text. LLMs have revolutionized the field of natural language processing, but they do come with certain limitations:
- Hallucinations: LLMs sometimes generate factually inaccurate or ungrounded information, a phenomenon known as “hallucinations.”
- Stale data: LLMs are trained on a static dataset that was current only up to a certain point in time. This means they might not have information about events or developments that occurred after their training data was collected.
- No access to users’ local data: LLMs don’t have access to a user’s local data or personal databases. They can only generate responses based on the knowledge they were trained on, which can limit their ability to provide personalized or context-specific responses.
- Token limits: LLMs have a maximum limit on the number of tokens (pieces of text) they can process in a single interaction. Tokens in LLMs are the basic units of text that the models process and generate. They can represent individual characters, words, subwords, or even larger linguistic units. For example, the token limit for OpenAI’s gpt-3.5-turbo is 4096.
Retrieval-augmented generation (RAG)
The retrieval-augmented generation (RAG) architecture was developed to address these issues. RAG uses vector search to retrieve relevant documents based on the input query. It then provides these retrieved documents as context to the LLM to help generate a more informed and accurate response. That is, instead of generating responses purely from patterns learned during training, RAG uses those relevant retrieved documents to help generate a more informed and accurate response. This helps address the above limitations in LLMs. Specifically:
- RAGs minimize hallucinations by grounding the model’s responses in factual information.
- By retrieving information from up-to-date sources, RAG ensures that the model’s responses reflect the most current and accurate information available.
- While RAG does not directly give LLMs access to a user’s local data, it does allow them to utilize external databases or knowledge bases, which can be updated with user-specific information.
- Also, while RAG does not increase an LLM’s token limit, it does make the model’s use of tokens more efficient by retrieving only the most relevant documents for generating a response.
This tutorial demonstrates how the RAG architecture can be leveraged with Atlas Vector Search to build a question-answering application against your own data.
The architecture of the application looks like this:
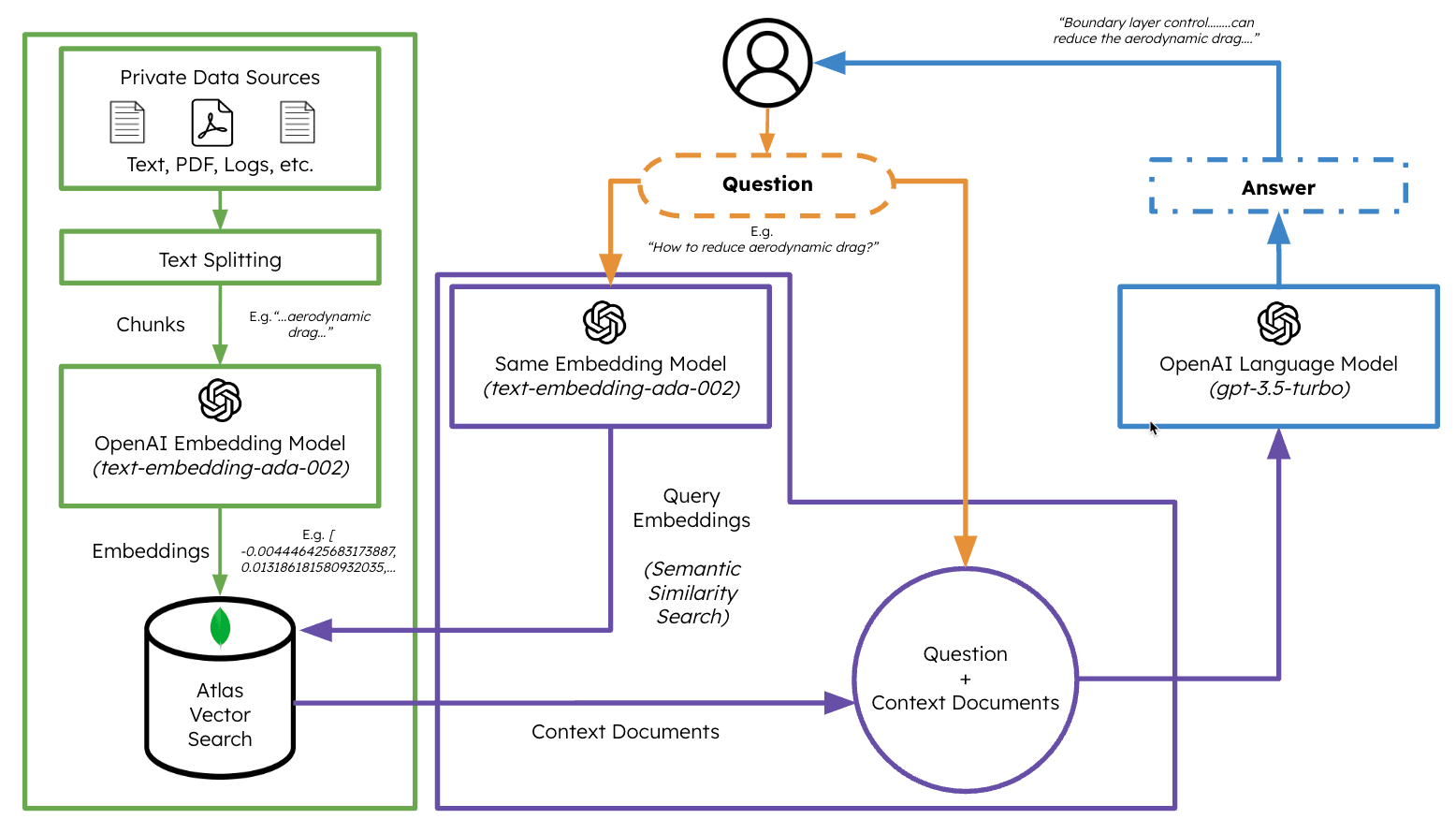
Note: For simplicity purposes, the Gradio component used for generating the application’s web-interface has not been shown in this architecture diagram.
In the following section, we will briefly discuss the different frameworks, models, and components that we will use in this tutorial, while trying to understand the nuances of some of these components.
MongoDB Atlas Vector Search allows you to perform semantic similarity searches on your data, which can be integrated with LLMs to build AI-powered applications. Data from various sources and in different formats can be represented numerically as vector embeddings. Atlas Vector Search allows you to store vector embeddings alongside your source data and metadata, leveraging the power of the document model. These vector embeddings can then be queried using an aggregation pipeline to perform fast semantic similarity search on the data, using an approximate nearest neighbors algorithm.
LangChain is a framework designed to simplify the creation of LLM applications. It provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications. This allows AI developers to build LLM applications that leverage external sources of data (for example, private data sources).
Some key things to note about LangChain:
- A “chain” in LangChain is a sequence of components that can be combined together to solve a specific problem/perform a specific task.
- A chain can include components and modules such as wrappers for LLMs and vector stores, prompt templates, loaders, text splitting and chunking modules, retrievers, etc. Different components can be chained together.
- The chain takes the user's input and processes it through each component in the sequence.
This modular approach of chaining different components or modules simplifies complex application development, debugging, and maintenance. - LangChain is an open-source project launched in October 2022. The project has quickly gained popularity. It is getting a lot of adoption, including contributions from hundreds of developers on GitHub, and has an ever increasing number of integrations with external systems. It’s not only gaining a lot of adoption but also evolving rapidly to meet the needs of its growing user base.
Gradio is an open-source Python library that is used to build a web interface for ML and data science applications.
OpenAI is an AI research company and is among a handful of companies that have been instrumental in the advancement of LLMs and generative AI. OpenAI has not only developed large language models that are gaining rapid adoption, but also has developed other models that perform a variety of other tasks such as text-vectorization, image generation based on language prompt, audio-to-text conversion, etc.
When someone refers to “using OpenAI” in their application, some disambiguation is necessary because there’s no one-size-fits-all model that can be used for all use-cases. In general, different models serve different purposes. For example, OpenAI’s GPT models are language models that understand and generate languages, the DALL-E model can create images based on a textual prompt, Whisper is a model that can convert audio into text, etc.
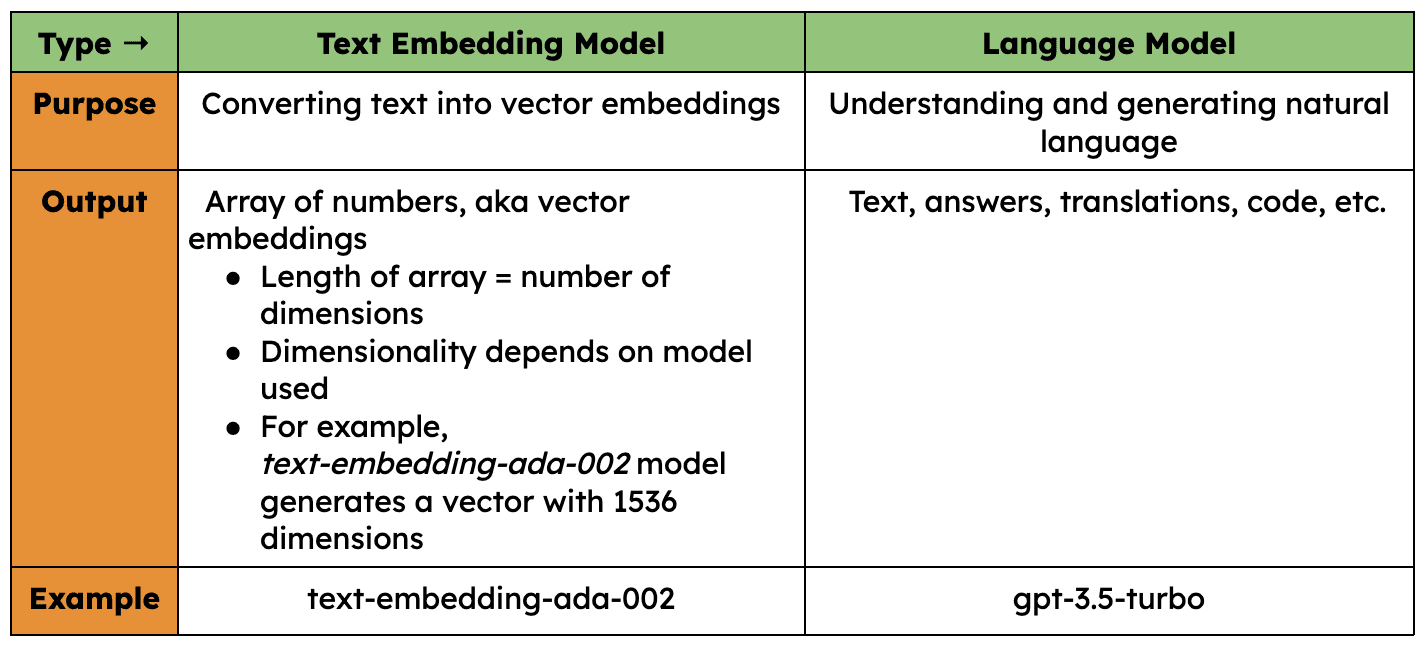
In this tutorial, we will be using OpenAI’s embedding model and language model. Therefore, it is important to understand the distinction between the two:
Main components
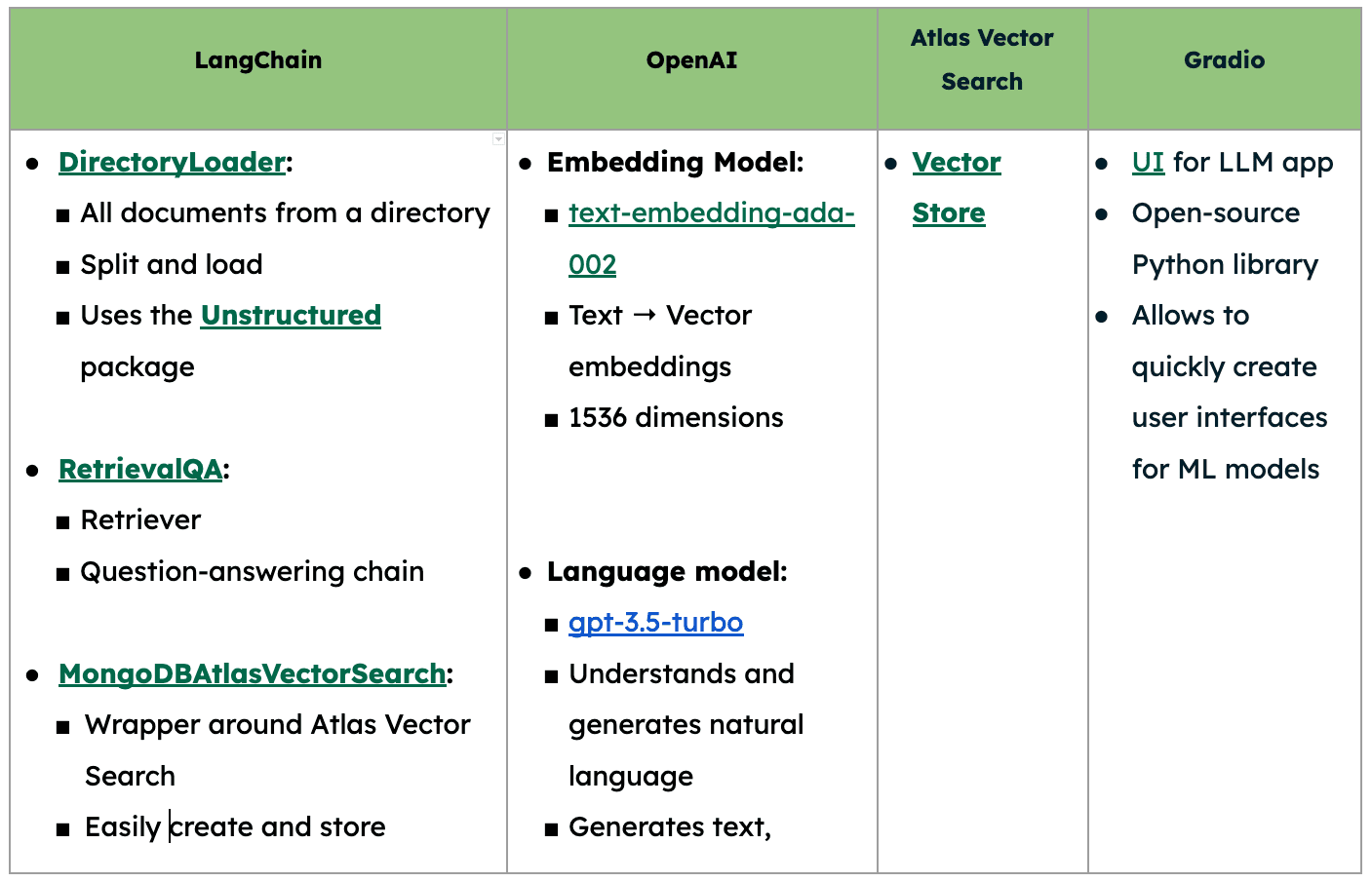
Note: The setup steps as well as the Python scripts shared below can be downloaded from the Github repo.
- Install the following packages:
- Create the OpenAI API key. This requires a paid account with OpenAI, with enough credits. OpenAI API requests stop working if credit balance reaches $0.
- Save the OpenAI API key in the key_param.py file. The filename is up to you.
- Optionally, save the MongoDB URI in the file, as well.
- Create two Python scripts:
- load_data.py: This script will be used to load your documents and ingest the text and vector embeddings, in a MongoDB collection.
- extract_information.py: This script will generate the user interface and will allow you to perform question-answering against your data, using Atlas Vector Search and OpenAI.
- Import the following libraries:

Sample documents
In this tutorial, we will be loading three text files from a directory using the DirectoryLoader. These files should be saved to a directory named sample_files. The contents of these text files are as follows (none of these texts contain PII or CI):
- log_example.txt
- chat_conversation.txt
- aerodynamics.txt
Loading the documents
- Set the MongoDB URI, DB, Collection Names:
- Initialize the DirectoryLoader:
- Define the OpenAI Embedding Model we want to use for the source data. The embedding model is different from the language generation model:
- Initialize the VectorStore. Vectorise the text from the documents using the specified embedding model, and insert them into the specified MongoDB collection.
- Create the following Atlas Search index on the collection, please ensure the name of your index is set to
default:
Performing vector search using Atlas Vector Search
- Set the MongoDB URI, DB, and Collection Names:
- Define the OpenAI Embedding Model we want to use. The embedding model is different from the language generation model:
- Initialize the Vector Store:
- Define a function that a) performs semantic similarity search using Atlas Vector Search (note that I am including this step only to highlight the differences between output of only semantic search vs output generated with RAG architecture using RetrieverQA):and, b) uses a retrieval-based augmentation to perform question-answering on the data:
- Create a web interface for the app using Gradio:
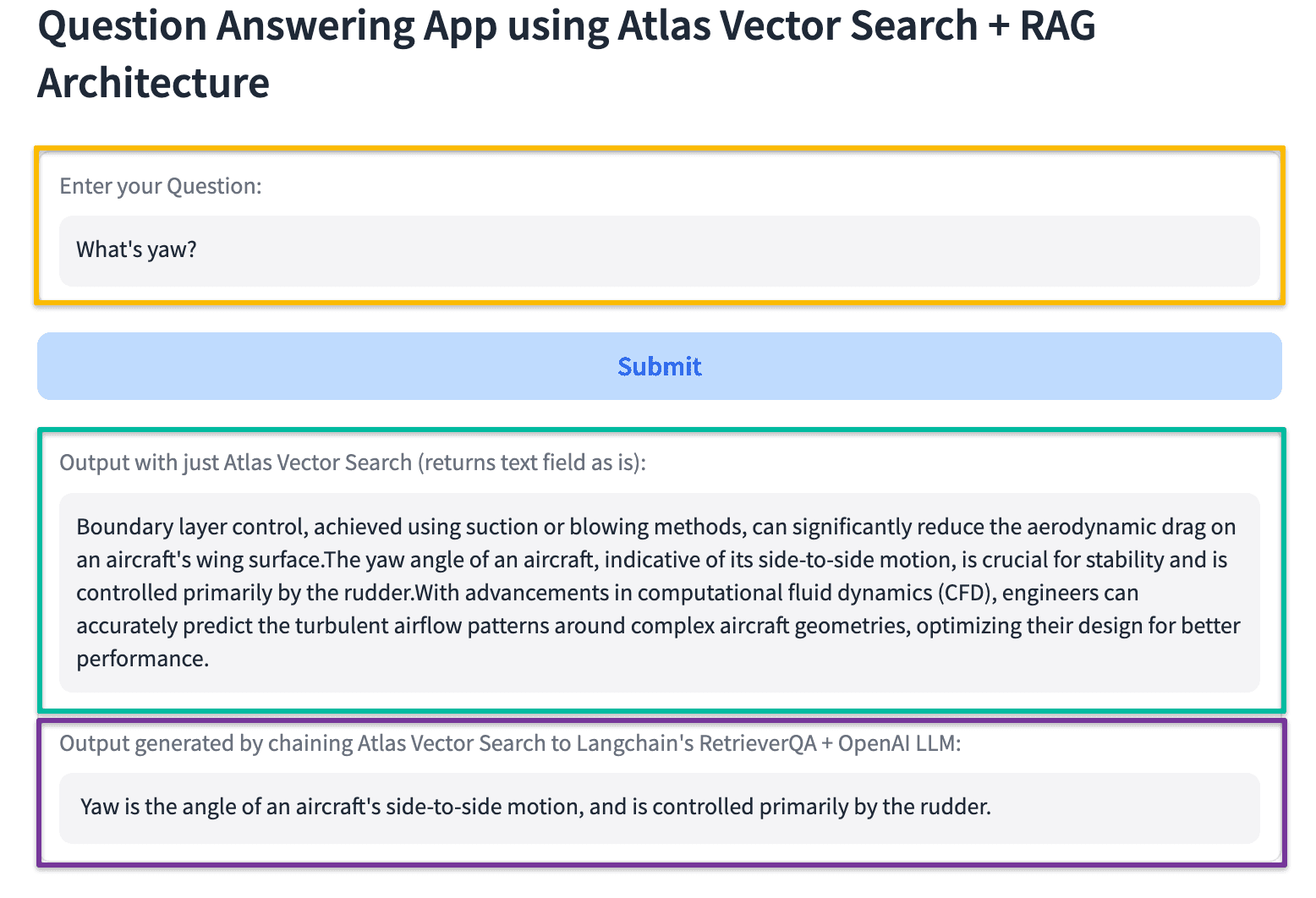
The following screenshots show the outputs generated for various questions asked. Note that a purely semantic-similarity search returns the text contents of the source documents as is, while the output from the question-answering app using the RAG architecture generates precise answers to the questions asked.
Log analysis example

Chat conversation example

Sentiment analysis example

Precise answer retrieval example
In this tutorial, we have seen how to build a question-answering app to converse with your private data, using Atlas Vector Search as a vector store, while leveraging the retrieval-augmented generation architecture with LangChain and OpenAI.
Vector stores or vector databases play a crucial role in building LLM applications, and retrieval-augmented generation (RAG) is a significant advancement in the field of AI, particularly in natural language processing. By pairing these together, it is possible to build powerful AI-powered applications for various use-cases.
Rate this tutorial

