Introduction to LangChain and MongoDB Atlas Vector Search







Rate this tutorial


In this tutorial, we will leverage the power of LangChain, MongoDB, and OpenAI to ingest and process data created after ChatGPT-3.5. Follow along to create your own chatbot that can read lengthy documents and provide insightful answers to complex queries!
LangChain is a versatile Python library that enables developers to build applications that are powered by large language models (LLMs). LangChain actually helps facilitate the integration of various LLMs (ChatGPT-3, Hugging Face, etc.) in other applications and understand and utilize recent information. As mentioned in the name, LangChain chains together different components, which are called links, to create a workflow. Each individual link performs a different task in the process, such as accessing a data source, calling a language model, processing output, etc. Since the order of these links can be moved around to create different workflows, LangChain is super flexible and can be used to build a large variety of applications.
MongoDB integrates nicely with LangChain because of the semantic search capabilities provided by MongoDB Atlas’s vector search engine. This allows for the perfect combination where users can query based on meaning rather than by specific words! Apart from MongoDB LangChain Python integration and MongoDB LangChain Javascript integration, MongoDB recently partnered with LangChain on the LangChain templates release to make it easier for developers to build AI-powered apps.
- MongoDB Atlas account
Our first step is to ensure we’re downloading all the crucial packages we need to be successful in this tutorial. In Google Colab, please run the following command:

Here, we’re installing six different packages in one. The first package is
langchain (the package for the framework we are using to integrate language model capabilities), pypdf (a library for working with PDF documents in Python), pymongo (the official MongoDB driver for Python so we can interact with our database from our application), openai (so we can use OpenAI’s language models), python-dotenv (a library used to read key-value pairs from a .env file), and tiktoken (a package for token handling).Once this command has been run and our packages have been successfully downloaded, let’s configure our environment. Prior to doing this step, please ensure you have saved your OpenAI API key and your connection string from your MongoDB Atlas cluster in a
.env file at the root of your project. Help on finding your MongoDB Atlas connection string can be found in the docs.Please feel free to name your database, collection, and even your vector search index anything you like. Just continue to use the same names throughout the tutorial. The success of this code block ensures that both your database and collection are created in your MongoDB cluster.
We are going to be loading in the
GPT-4 Technical Report PDF. As mentioned above, this report came out after OpenAI’s ChatGPT information cutoff date, so the learning model isn’t trained to answer questions about the information included in this 100-page document.The LangChain package will help us answer any questions we have about this PDF. Let’s load in our data:
In this code block, we are loading in our PDF, using a command to split up the data into various chunks, and then we are inserting the documents into our collection so we can use our search index on the inserted data.
To test and make sure our data is properly loaded in, run a test:
Your output should look like this:
![output from our docs[0] command to see if our data is loaded correctly](index7f38.html?url=https%3A%2F%2Fimages.contentstack.io%2Fv3%2Fassets%2Fblt39790b633ee0d5a7%2Fbltffc8c7af0758989d%2F65733c20c6be9382d6e0256f%2Flanchain1.png&w=3840&q=75)
Let’s head over to our MongoDB Atlas user interface to create our Vector Search Index.
First, click on the “Search” tab and then on “Create Search Index.” You’ll be taken to this page. Please click on “JSON Editor.”
Please make sure the correct database and collection are pressed, and make sure you have the correct index name chosen that was defined above. Then, paste in the search index we are using for this tutorial:
These fields are to specify the field name in our documents. With
embedding, we are specifying that the dimensions of the model used to embed are 1536, and the similarity function used to find the nearest k neighbors is cosine. It’s crucial that the dimensions in our search index match that of the language model we are using to embed our data.Once set up, it’ll look like this:
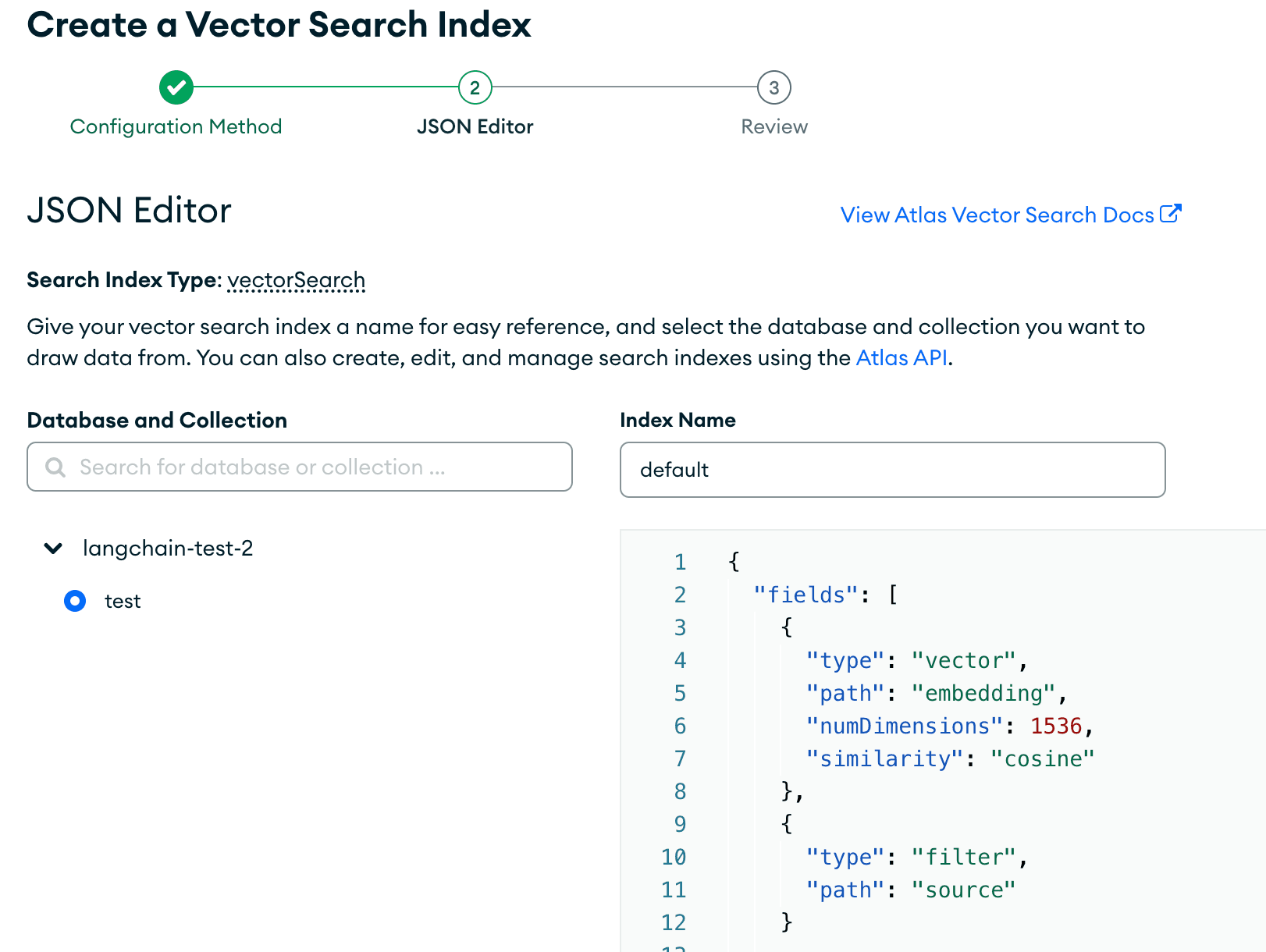
Create the search index and let it load.
Now, we’re ready to query our data! We are going to show various ways of querying our data in this tutorial. We are going to utilize filters along with Vector Search to see our results. Let’s get started. Please ensure you are connected to your cluster prior to attempting to query or it will not work.
To get started, let’s first see an example using LangChain to perform a semantic search:
This gives the output:

This gives us the relevant results that semantically match the intent behind the question. Now, let’s see what happens when we ask a question using LangChain.
Run this code block to see what happens when we ask questions to see our results:
After this is run, we get the result:
This provides a succinct answer to our question, based on the data source provided.
Congratulations! You have successfully loaded in external data and queried it using LangChain and MongoDB. For more information on MongoDB Vector Search, please visit our documentation
Rate this tutorial