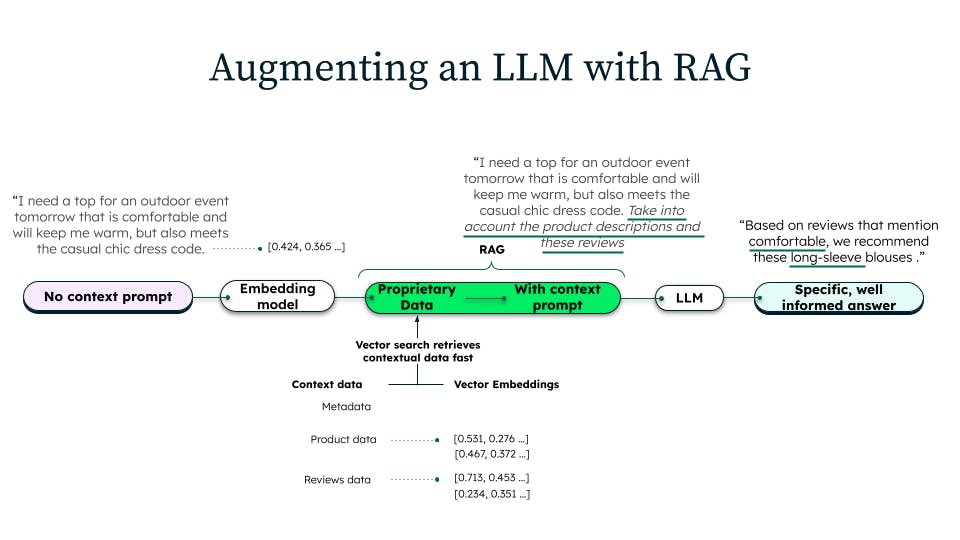
As a workaround for this lack on domain-specific context, retrieval-augmented generation is performed as follows:
- We fetch the most relevant product descriptions from a database (often a database with vector search) that contains the latest product catalog
- Then, we insert (augment) these descriptions into the LLM prompt
- Finally, we instruct the LLM to “reference” this up-to-date product information in answering the question
Three things to consider from the above:
- Retrieval-augmented generation is a purely inference time (no retraining required) technique. The above steps 1-3 all happen in inference-time. No changes to the model are required (e.g. modifying the model weights).
- Retrieval-augmented generation is well suited for real-time customizations of LLM generations. Because no retraining is involved and everything is done via in-context learning, RAG-based inference is fast (sub 100ms latency), and well suited to be used inside real-time operational applications.
- Retrieval-augmented generation makes LLM generations more accurate and useful. Each time the context changes, the LLM will generate a different response. Thus, RAG makes LLM generations depend on whatever context was retrieved.
To achieve a performant, yet minimally complex RAG architecture, it starts with choosing the right systems. When choosing the systems, or technologies, for a RAG implementation, it is important to choose systems, or a system, that can achieve the following:
- Support new vector data requirements without adding tremendous sprawl, cost, and complexity to your IT operations.
- Ensure that the generative AI experiences built have access to live data with minimal latency.
- Have the flexibility to accommodate new data and app requirements and allow development teams to stay agile while doing so.
- Best equip dev teams to bring the entire AI ecosystem to their data, not the other way around.
Options range from single purpose vector databases, to document and relational databases with native vector capabilities, and data warehouses and lakehouses. However, single purpose vector databases will immediately add sprawl and complexity. Data warehouses and lakehouses are inherently designed for long-running analytical type queries on historic data as opposed to the high volume, low latency and fresh data requirements of the GenAI apps that RAG powers. Additionally, relational databases bring rigid schemas that limit flexibility of adding new data and app requirements easily. That leaves document databases with native, or built-in, vector capabilities. In particular, MongoDB is built on the flexible document model and has native vector search, making it a vector database for RAG in addition to the industry leading database for any modern application.
Taking the power of LLMs to the next level with additional capabilities in your RAG implementation.
In addition to the core components, there are a number of additional capabilities that can be added to a RAG implementation to take the power of LLMs to the next level. Some of these additional capabilities include:
- Multimodality: Multimodal RAG models can generate text that is based on both text and non-text data, such as images, videos, and audio. Having this multimodal data stored side by side with live operational data makes the RAG implementation more easy to design and manage.
- Defining additional filters in the vector search query: The ability to add keyword search, geospatial search, and point and range filters on the same vector query can add accuracy and speed to the context provided to the LLM.
- Domain specificity: Domain-specific RAG models can be trained on data from a specific domain, such as healthcare or finance. This allows the RAG model to generate more accurate and relevant text for that domain.
There are a number of things that can be done to ensure that a GenAI-powered application built with a RAG is secure, performant, reliable, and scalable when it goes global. Some of these things include:
- Use a platform that is secure and has the proper data governance capabilities: Data governance is a broad term encompassing everything you do to ensure data is secure, private, accurate, available, and usable. It includes the processes, policies, measures, technology, tools, and controls around the data lifecycle. Thus, the platform should be secure by default, have end-to-end encryption, and have achieved compliance at the highest levels.
- Use a cloud-based platform: In addition to the security and scalability features cloud-based platforms provide, the major cloud providers are some of the leading innovators for AI infrastructure. Choosing a platform that is cloud agnostic allows the ability for teams to take advantage of the AI innovations wherever they land.
- Use a platform that can isolate vector workload infrastructure from other database infrastructure: It is important that regular OLTP workloads and vector workloads do not share infrastructure so that the two workloads can run on hardware optimized for each, and so that they do not compete for resources while still being able to leverage the same data.
- Use a platform that has been proven at scale: It’s one thing for a provider to say it can scale, but does it have a history and a track record with global, enterprise customers? Does it have mission critical fault tolerance and ability to scale horizontally, and can it prove it with customer examples?
By following these tips, it is possible to build GenAI-powered applications with RAG architectures that are secure, performant, reliable, and scalable.
With the introduction of Atlas Vector Search, MongoDB’s leading developer data platform provides teams with a vector database that enables building sophisticated, performant RAG architectures that can perform at scale. All this while maintaining the highest levels of security and cloud agnosticism, and most importantly, without adding complexity and unnecessary costs.